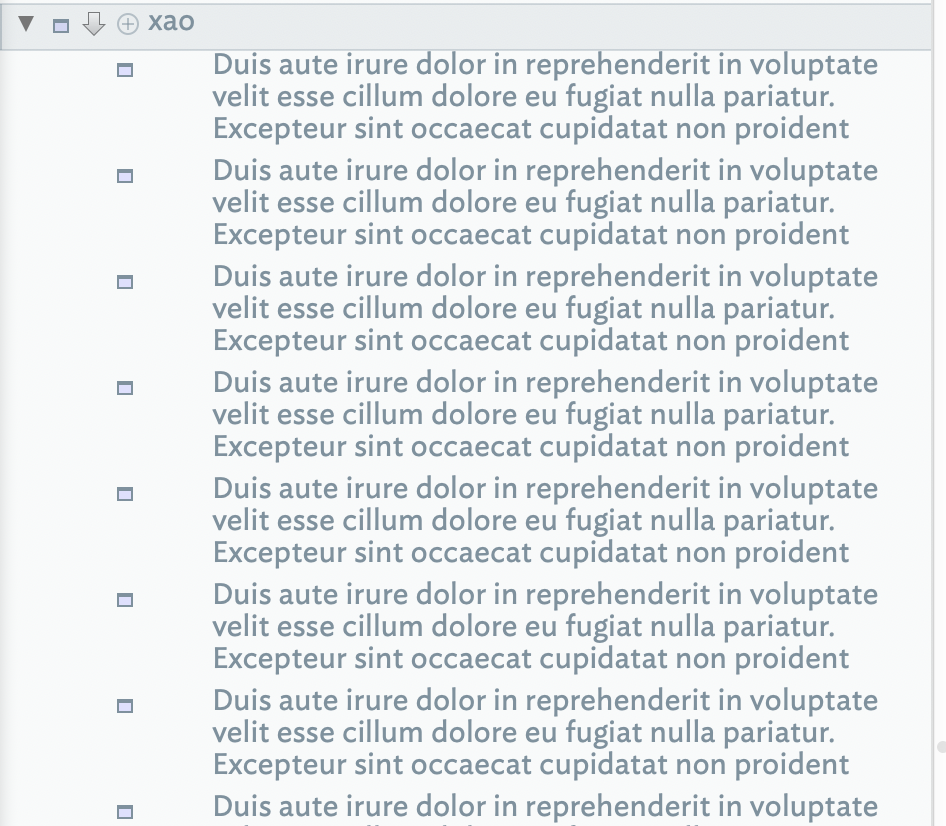
Ah. It turns out on closer inspection that the TXT file import reported above is not as I expected (apologies, it was late here and I posted the result without deeper inspection). So, my split files each hold 500 repeated single paragraphs each with the text:
Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim ven.
What the import has done is take the first sentence and a bit more as the note title:
Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident
and then parsed the rest into user attributes:
Why. I’m not sure. If I make a file with just one paragraph of the test text, it imports as a note names as for the file (without extension) and the contents of the file is the $Text.
Curiouser still, was the result of making a file with two short paragraphs:
Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore.
Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore.
as this imports as one note with the $Text as per the source file contents.
This outcome suggests that the length is the first line (paragraph) or possibly the source text overall is affecting how the fill import works. Bottom line, results are like inconsistent using this method as the parsing logic as to when to generate multiple notes is as yet unclear. Pinging: @eastgate