The tag-matching feels a bit hacky and I’m sure could be done better. I also think there’s probably a way to find notes that are fully-tagged (i.e. all §tags have been added to $Tags) and notes with missing tags (i.e. some §tags haven’t made it into $Tags yet). But this is what I’ve got for now
Extraordinary. I never cease to be amazed at how quickly people can put together these things. Thank you. I will store that up for future use. Mind you, any time I see code with the letters “var” in it, I know I am out of my depth. I took an aptitude test for programming about forty years ago, and they told me to forget it!
I’m coming to see that the totemic nature of ‘tags’ is as unhelpful as that of hierarchies. ‘tags’ are simply a more recent word for ‘keywords’ (probably as it sounded cooler and less techie) which are themselves simply metadata. A value in $MyString as as much of a ‘tag’ as a value in $Tags. But, of course, if tags are the only metadata one has been offered for keywording one’s data it’s unsurprising that it is hard to see the bigger picture.
Using tags, or rather one bucket for all your custom metadata, isn’t necessarily helpful. Mapping tags ingested form other apps to $Tags can be initially useful to provide coherence/sync. But beyond that, or if generating data from scratch within Tinderbox, there’s little upside to putting all your metadata in one field/attribute/list. If you take someone’s contact info, you wouldn’t put all the address, zip, phone, email, etc., into tags as it would make it far harder to find, say, that person’s street. In the same way, gaining comfort to split out your tag-bucket into discrete attributes (of ‘fields’ if you prefer) starts to unlock being able to do more with your information.
To close, their’s nothing wrong with sticking to hierarchical outlines and single-tag-bucket practices learnt in the past. However, to move beyond that limited practice is to take the training wheels of your use of Tinderbox. A database would want you to define all your attributes before you know you really need them. A strength of Tinderbox is you don’t need to do that - add new attributes as you see a need for them.
Very interesting. I like the contact info analogy. I like the idea of letting the structuring information emerge from the data as it is perused and understood, too. It reminds me of doing qualitative studies in psychology. Miles and Huberman, where are you?
Indeed, we’re in agreement and I don’t think I’m altering your point but expanding another aspect of it. sme folk only know of ‘tags’ as other tools only offer one method of keywording.
To help flesh out some ideas expressed above, I’ve shown some of my own current early stage work. To avoid thread drift it is in a separate thread, here.
The whole discussion is interesting… but I wonder if useful, except that it proves we love exchanging.
Examples might help. I associate User attributes to some permanently recurring dimensions that I need in order to characterize the notes, that permit me to move the notes, to classify the note, whereas “tags” allow to indicate information related to the content of the note. Tags are as variable and diverse as the words in the content of the note. Tags are like underlined words in a book.
User attributes are like the handles of the tools you use to move the notes, whereas tags are part of what you shovel around. They just indicate content. Thinking is wometimes about moving things around (user attributes help in doing this) whereas keywords are like flags, colors, visible signs about the content.
And then you have Mark Andeson who has better examples…
Having said that here is a question: how can I collect all the tags in one key attribute (called “Tags”) in one list of all tags?
For example:
Note 1
Tags : Blue, fruits, painting
Note 2
Tags : Yellow, fear, policy, workers union
Result of the exercise would be a list of tags :
Blue
fear
fruits
painting
policy
workers union
Yellow
Any suggestions ? Probably involves exporting this user attribute.
Collecting all tags into a master list could be done with an agent that queries every note with non-null tags, and adds them to a set attribute in a certain “collector” note.
Use the values() operator, which is designed for just this. See the linked article for detail on the scope/syntax. But for instance, to get a Set (i.e. no dupes) of all $Tags values:
$MySet = values("Tags");
I often use this pattern. Let’s say I want to make a new note for each discrete author in references I’ve imported. I Make a new note and give it this rule;
$Text=values("Authors").isort.format("\n");
That gives me a sorted list of names, one per line in the note’s text. I can then explode the note and I’ve then got a note per author. I use this a lot in my own research to drill down into metadata (i.e. user attributes) I’ve populated when working on the source data (e.g. the example I posted a link to a few posts above). In that case I’ll definitely be extracting a list of editors in a thread so I can compare it with a list (from another TBX) so I can identify which participants are also bot operators.
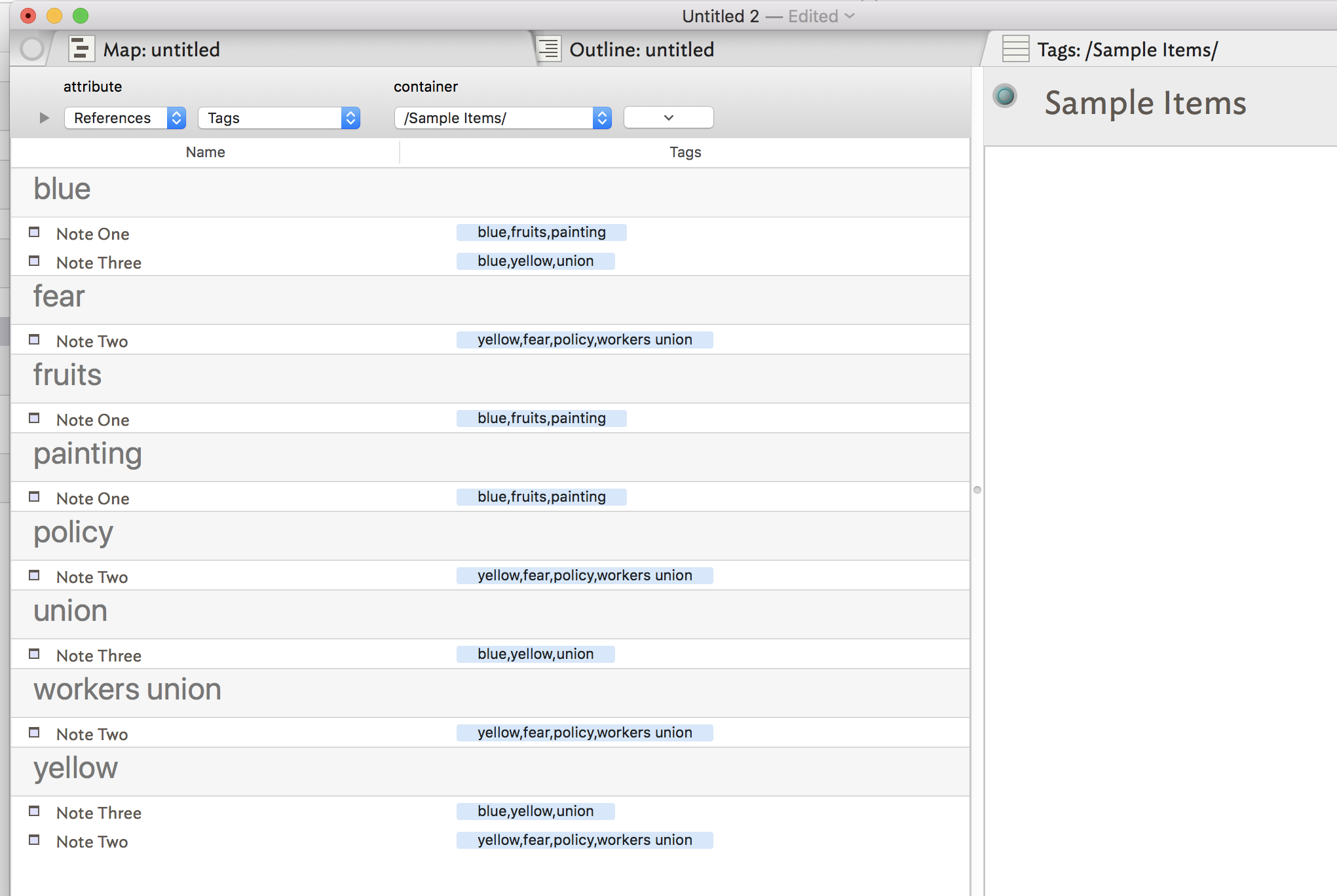
In addition to the suggestions from Mark A and Paul W, here is another case where the attribute browser can be your friend. Using just the data for Note 1 and Note 2 that you set out above, plus a note Note 3 that shares some tags with the previous two, with literally two minutes’ work you can put together this attribute browser view. It groups all the notes under each relevant tag. At the same time, it can show you, in the column on the right, the complete list of tags that each note has.
This is showing you something different from the list that @mwra produced, but it’s another way to look at the data. But it might also be a way of getting toward what you’re looking for. (If you have three minutes rather than two, you can refine this in all sorts of ways – sorting the items in each grouping, ruling-in or ruling-out certain tags or certain items; etc.
This obviously becomes more useful when you have not three items but many hundreds – for instance, when I’m working on an article or book, I assign theme or topic categorizations to material as I receive it. Then when I am working on the writing, I can see which 8 or 10 references, out of hundreds or thousands in total, are relevant to the theme I’m working on. And in other columns in the view I can see what other categorizations I’ve given those items, what the original source was, whether I’ve included them in previous drafts, etc.
I’d agree with @PaulWalters and add also that it’s ‘tags AND’ not ‘tags OR’ and - as I write @JFallows sensible prod for using the under-used Attribute Browser (for which feature I think we owe @JFallows some kudos).
Initially @MartinBoycott-Brown probably does want to use $Tags - or any Set-type attribute (so as to avoid duplicate values). Tip: for a new project of this type don’t over-look ‘suggested values’ to speed data entry. It I was using this close reading technique, I’d consdier using some scipt (outside TB) that I could import and explode to give me notes equating to chapter/page/numbered paragraphs. By using structured input and prototypes I could seed some of the details @PaulWalters sensibly suggests.
The or-vs-and part relates to teasing nuance out of initial tags. So, you mention ‘deportment’ so for all notes with the the $Tags ‘deportment’ you might want to revisit, using the back-references @PaulWalters suggests to add nuance as to why/how this subject is mentioned. This extra finesse of metadata makes it easier to find ‘deportment’ mentions for reason X vs. reason Y - something tags likely won’t give.
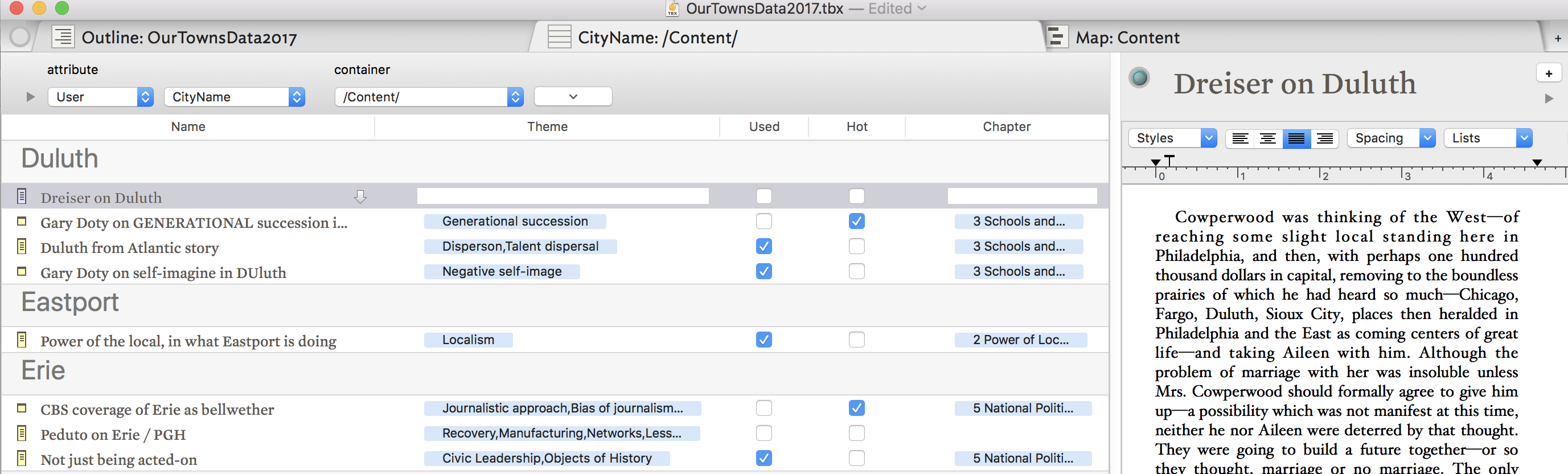
I find all these discussions really interesting. Here’s an additional real-world illustration, of the way I use the sainted Attribute Browser to manage large quantities of thematic data:
As I’ve been collecting data for a writing project, I can assign values to it on the way in – themes I think it applies to, cities it applies to (for a city-structured narrative), whether or not it’s been used, etc. And of course as I go along I can add, subtract, shift, change, discard, etc those assignments.
Then I can use those various categorizations to affect how I see the info. Here is the view I might want to look at while writing about particular cities:
The really important thing about the attribute browser is that, in adjoining always-available tabs, I can see the same corpus of data sliced-and-diced in a different way, For instance, at the next tab over, I have the data grouped not by city name but by theme:
This is a 100% crucial point. The built in attribute $Tags is just one of a virtually limitless set of categorizing terms you can create if and as you need them. Some I’ve used over the years include $Themes, $Points, $Contexts, $MainPoints, $ArticleThemes, $RefThemes, $BlogThemes, etc. They can be strings; they can be sets. They can come, and they can go.
In some programs, the existence of one built-“Tags” category would imply that you needed to cram every possible identifying trait into that. In Tinderbox it’s very different. In fact I realize just now that I’ve never actually used the built-in $Tags attribute. Have just created a range of to-my-taste counterparts.
My sincere thanks to everyone involved in these discussions.
I understand you (and as an aside, your analysis of the uses of tags and attributes is right, I think) but I can honestly say the whole discussion has been VERY useful to me (if not necessarily to others ;)) as it has allowed me to work out some of my ideas under the guiding presence of those who are better informed about what the program can do.
As a result, I believe I shall be using DEVONthink to store my pdfs and other source material, but I shall be using Tbx to work out what I THINK about the material. This is the step that was lacking before.
This is the division-of-labor I have found my way toward as well. DevonThink is built to stand up well in this kind of large-scale operation. Tinderbox is built for the strategic and creative work.