Dear Mr. Michael Becker,
I was just retaking the questions from a year ago.
Using your provided TBX L - CollectChildrenText.tbx
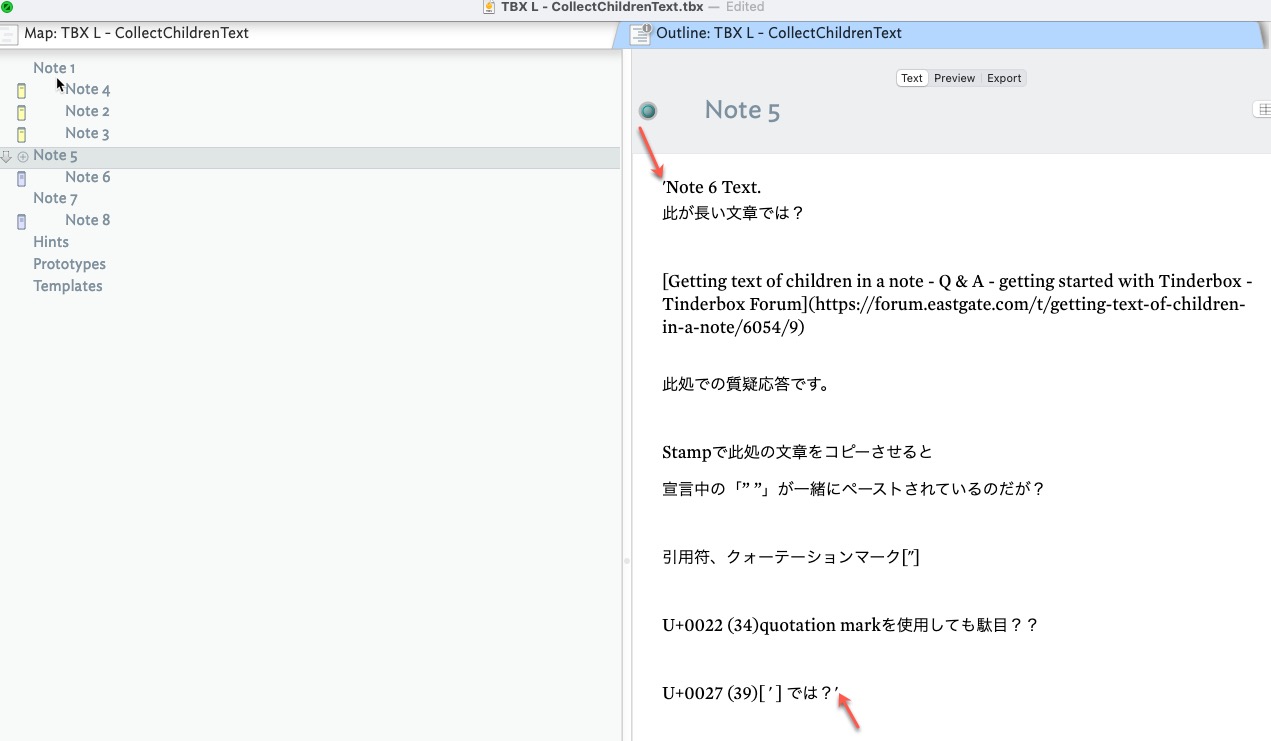
I tried to move the sentences in the Note, but the moved sentences
The “'” symbol remains at the beginning and end.
In short English sentences, such residual symbols do not occur,
When I move Japanese, the symbol “'” is displayed.
Do you have any solution?
I have looked here and still can not find a solution.
(String.replace(regexMatchStr, replacementStr))
The only accepted value for filterStr is
“punctuation”, in which case the operator also removes punctuation marks.
Is there a way to delete “quotation marks” instead of deleting punctuation marks?
I would be very happy if I could borrow your knowledge from you.
Sincerely yours, WAKAMATSU
Dear Mr. Michael Becker,
Found a solution.
Add .substr(1,-1) after your Collect Children stamp
It worked.
The newly registered stamps are as follows. $Text=collect(children,$Text).replace("^;","^\n").substr(1,-1);
Little by little, I came to understand the functions of Tinderbox.
I apologize for any concern.
In the meantime, I would like to continue my review.
Sincerely yours, WAKAMATSU
P.S.
The function does not matter whether the blank character “^” is inserted in the stamp or not.
It was the same.
P.P.S
Why does the quotation mark [ ’ ] remain
at the beginning and end when copying Japanese?
I would like to know the cause.
Can you share the stamp you’re using. It is not clear to me why it would be adding the ’ or ", this typically occurs when there is a character the TBX needs to escape, like a '/` or ‘(’, but I don’t see that in your example image. I wonder if there is something else going on.
Dear Mr. Michael Becker,
Thank you for checking out my features.
I have attached the Tinderbox file.
Below are my environment,
the stamps I use, and the conditions I used them in.
My circumstance: Mac mini 2014 (Intel)
Mac OS 11.7.9 Big Sur, Tinderbox 9.6.1(b638)
TBX L - CollectChildrenText is almost your original tbx.
Stamps:
Collect Children original : your original stamp
Collect Children : $Text=collect(children,$Text).replace(';','\n');
Collect Children 1 : $Text=collect(children,$Text).replace("^;","^\n");
Trim Children 1 : $Text=collect(children,$Text).replace(';','\n').substr(1,-1);
Trim Children 2 : $Text=collect(children,$Text).replace("^;","^\n").substr(1,-1);
Note 10 : use your original Stamp
Note 7 : use Trim Children 1
Note 5 : use Trim Children 2
I would appreciate it if you would consider it.
Sincerely, WAKAMATSU TBX L - CollectChildrenText.tbx (158.1 KB)
The reason you’re not getting the ’ is that you are collecting the $Text of the children. In the children (in this case a child) the text contains special characters (e.g. (, ), [, [, ") that Tinderbox needs to escape (this this because of regex processing, I’m not too sure on this point).
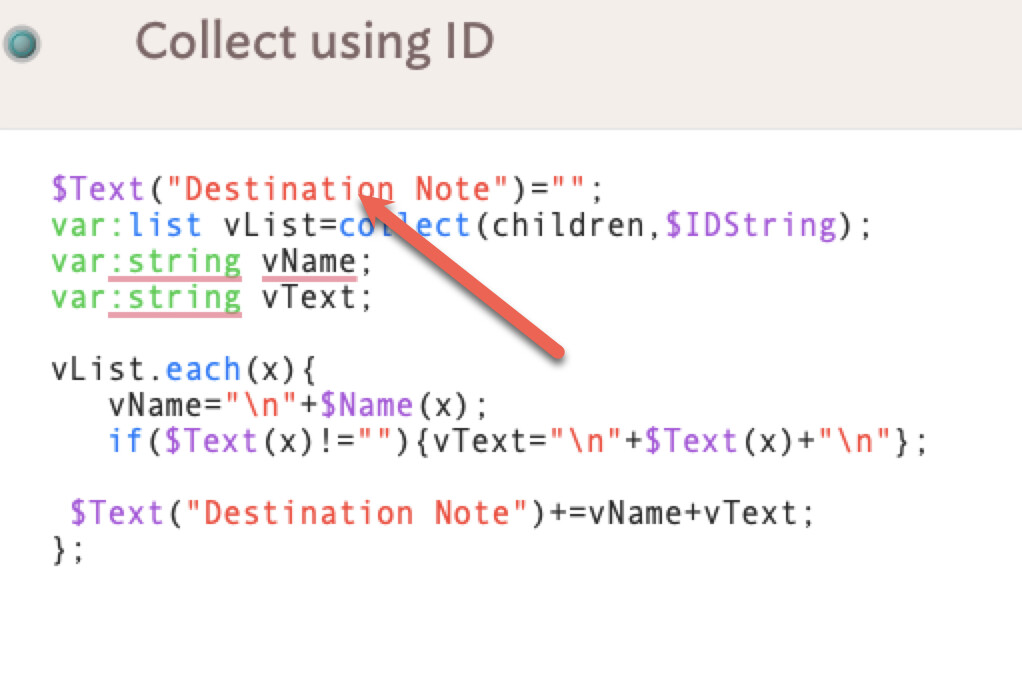
Unless I have a very specific use case, there is another way to do this. I’ve moved away from collecting specific attributes with collect; rather, I collect the $ID or $IDString of the children, and then from there, using a .each() operator, I can grab anything I want, e.g., $Name, $Text, or any other attribute value.
See here and the attached. You can apply this to any of your notes and the collected children will populate the note “Destination Note.”
Dear Mr.Michael Becker,
Thank you for your kind answers and guidance
and providing TBX L - CollectChildrenText Becker R2.tbx.
Your approach this time to a different method is just like
learning how to create “chord” harmony in music.
From which note should I stack up the notes?
Even with the same sound combination “Do & Mi & Sol”,
The basic form is based on Do, the first expansion is based on Mi,
and the second expansion is based on Sol.
The sound of each cluster is “different”
(though it may be difficult to distinguish between them if you are not an expert)
If we connect and execute this basic form and expanded form in succession,
We can add melodies with beautiful harmonies.
I do not think I can use this proposal yet,
I find it interesting to study because
I find commonalities with the world of music.
By the way,I have a few questions.
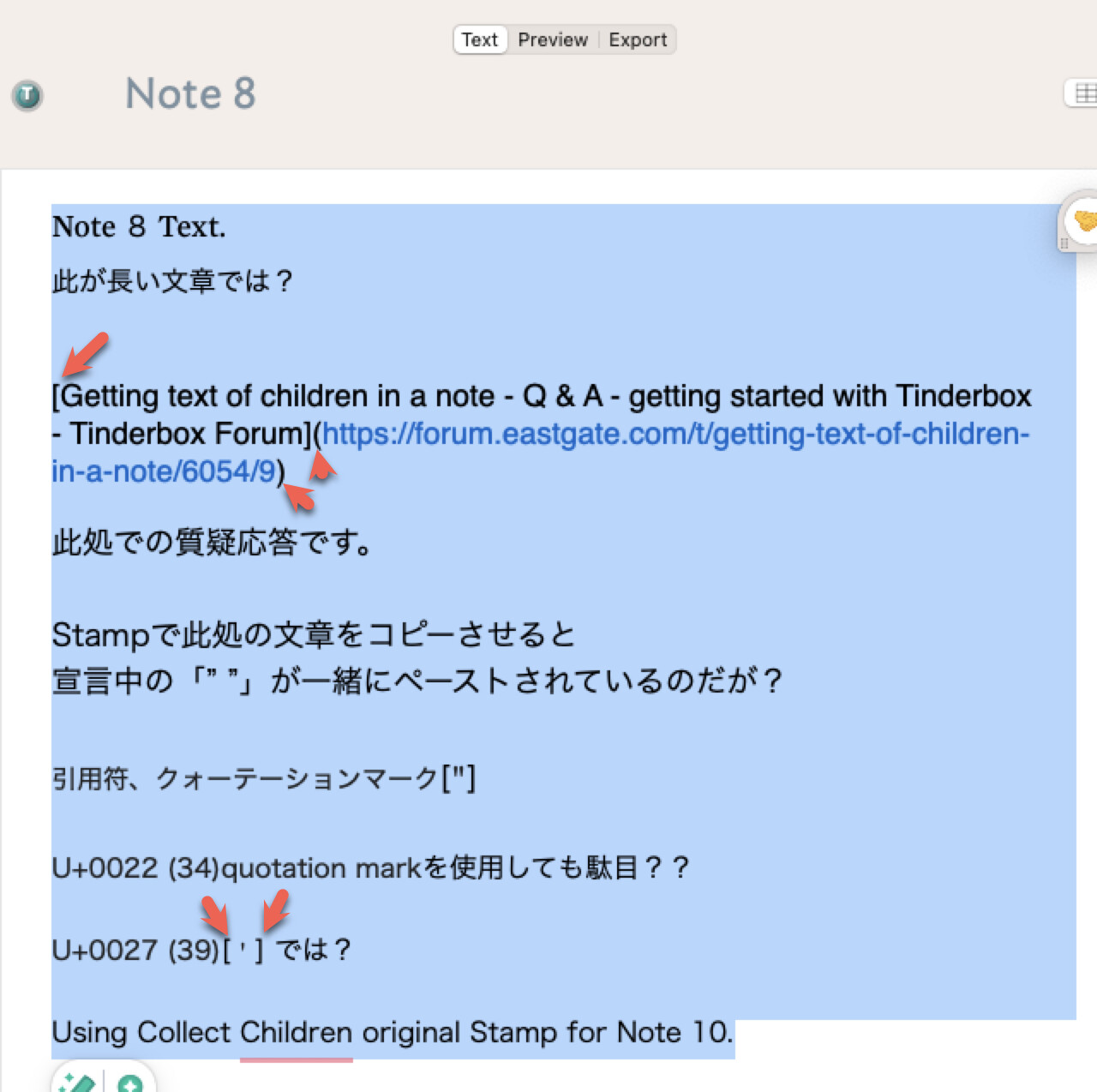
Q01a: From your post, [Contains special characters ((,), [, [, “, etc.) that need to be escaped.”
However, where is the information about this “child file” written?]
Q01b: Where should I look for reference?
Q02: If I want to create Destination Note2 etc. and branch,
what should I do rewrite the settings?
Q03: When writing to the current Destination Note,
How do I change it to make it work in order to add the “parent file name”?
(Currently, the child file name and text name are written
in addition to the main text.)
For $ID and $IDString, I will read “A Tinderbox Reference File” carefully,
increase my understanding.
I would appreciate it if you could give me a little more time
to digest and absorb the reference files you provided.
Sincerely yours, WAKAMATSU
TBX adds the " around the text to tell the parser to treat the text like a string and to not process the text as if it was a RegEx (at least this is that I believe is happening; @mwra may have a more accurate answer).
I’m not sure, maybe @mwra can help. @mwra, is there an article in TBX that explains what TBX is doing when it wraps a string in quotes to escape special characters, and which characters may trigger this behavior? I’m primarily learning from experience and muscle memory, I can’t say that I understand the actual mechanics and conditions on when these escapes occur.
You could manually create “Destination Note2” (Note: there are ways to automate this). In the stamp code change “Destination Note” to “Destination Note2”.
With this operation, what is happening is that you are telling Tinderbox to process the expression to the right of the equal sign (“=”) and to apply the result to the attribute on the left side of the equal “=” sign.
In this case, on the left side, we’re telling TBX to put the result of the express in the $Text of a notes named “Destinate Note”, i.e., we’re using a unique name offset, you could have equally set the offset as a path, e.g. “/Destinations/Destination Note2”. In this case it would l tool like this: $Text("/Destinations/Destination Note2")=...
NOTE: if you did not specify the offset, e.g., just said $Text=... then the expression would apply to the current note.
There are lots of different ways, maybe you do something list this:
Create a variable to capture the name of the current note. Then append that name with a designator, e.g. “:”, to each of the pulled chile notes.
Dear Mr.Michael Becker,
Thank you for your kind guidance.
Unfortunately,this is a disappointing report.
In the stamp code change “Destination Note” to “Destination Note2”.
Writing with this specification change does not work for some reason.
I had already tried specifying this as “Destination Note2”, but
For some reason it doesn’t work, so I asked “How should I rewrite it?”
in the question.
I need added something ?
Why does the part with var:String vName not work?
I still have something to add, but where ?
Is there a problem? ?
Yours, WAKAMATSU
Dear Mr.Michael Becker,
I am still in a fog.
Is there a misunderstanding due to a lack of explanation
between my understanding and interpretation of what I requested?
$Text(“/Destinations/Destination Note2”)=…
This change will cause the contents of the specified document
to be included in the Destination file.
Does this mean it will be added?
My intention is to create a new file called Destination Note2.
I was wondering about the description to write the specified document?
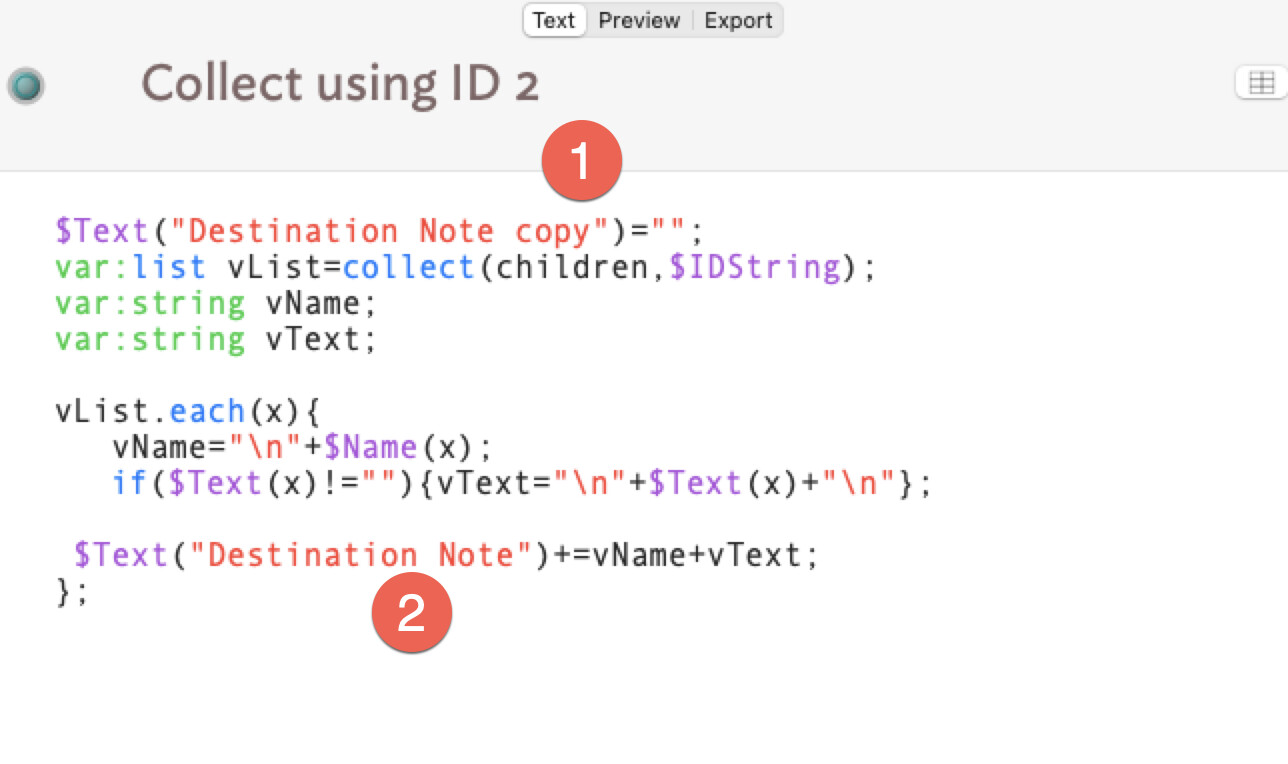
The steps I’ve tried so far are #01: Duplicate Destination Note and rename it to Destination Note Copy #02: At Stamps
Duplicate Collect using ID and rename it to Collect using ID 2 #03: The opening statement of Collect using ID Copy was rewritten as follows.
$Text(“Destination Note copy”)=“”;
#04: At the end of the Destination Note text
—————2023-09-11-105831 inserted for confirmation.
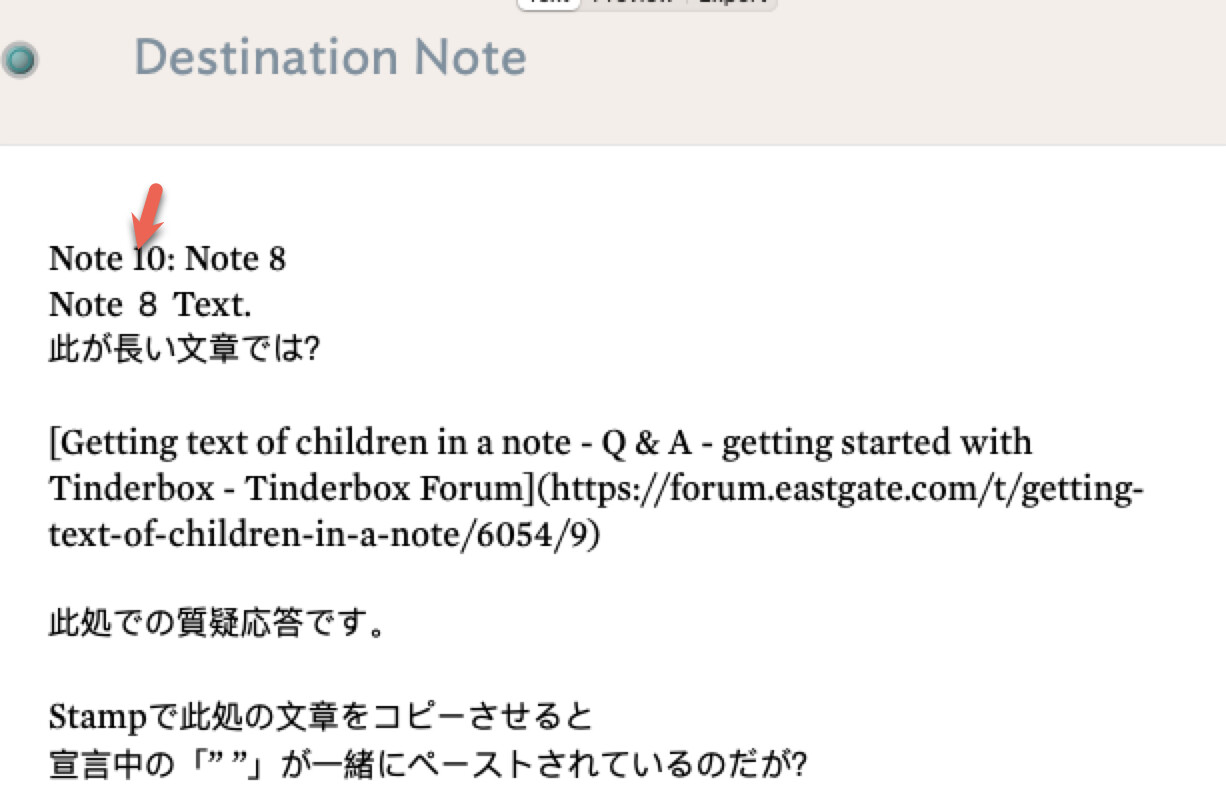
#05: The child file of Note10 was changed to Note 8a so that it can be identified.
#06: Execute Stamp [Collect using ID 2] using Note 10.
#07: The execution result is
After the inserted description of —————2023-09-11-105831 in Destination Note
Note 8a
Note 8a Text.
(…more sentences continue)
In the above situation,
Destination Note Copy does not show any document writing.
How to change the description to Destination Note Copy (or Destination Note2)
Can I copy and move the contents of the desired file?
Thank you very much for your guidance.
Yours,WAKAMATSU TBX L - CollectChildrenText Becker R2-modification.tbx (206.2 KB)
You need to change the name in two places. The first reference clears the destination note and the second writes to the destintation note. You need to add “Destination note copy” to the sectond reference, too.
In Note 10 I added a new attribute, this holds the name of the destination note. I also created a “Destination Notes Folder”.
I then added a new stamp “Collect and Create using ID.” This stamp will create a new note from the value in the DestiantionNoteName attribute and the populate the text of the note.
Dear Mr.Michael Becker,
Thank you for providing TBX L - CollectChildrenText Becker R3-modification.tbx.
I changed the name of the Stamp writing in this
TBX L - CollectChildrenText Becker R2-modification.tbx,
to “Destination Note2” in two places and executed it.
It worked without any problems and wrote to “Destination Note2”.
However, what is strange is that even though
I posted the same post two days ago,
It will not write to “Destination Note2”.
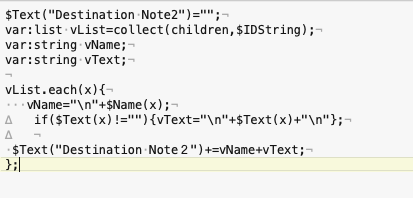
I just saw the name [Collect using ID 1]. ?
This stamp doesn’t work.
The file used is “TBX L - CollectChildrenText Becker R2.tbx”
The settings are written as shown below,
so they should be exactly the same, right?
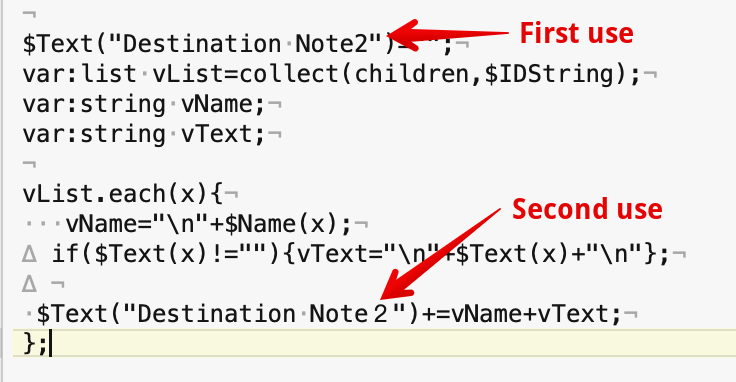
$Text(“Destination Note2”)=“”;
var:list vList=collect(children,$IDString);
var:string vName;
var:string vText;
$Text(“Destination Note2”)+=vName+vText;
};
Why do the same files behave differently?
From my observations, I couldn’t find the cause.
In your judgment, are there any contributing factors?
What do you think?
Yours, WAKAMATSU
P.S
Attach the initial file
[TBX L - CollectChildrenText Becker R2.tbx]in question.
After dinner, I am thinking of trying out the new
[TBX L - CollectChildrenText Becker R3-modification.tbx] you gave me.
September 11, 2023 15:48:26 JST TBX L - CollectChildrenText Becker R2.tbx (209.2 KB)
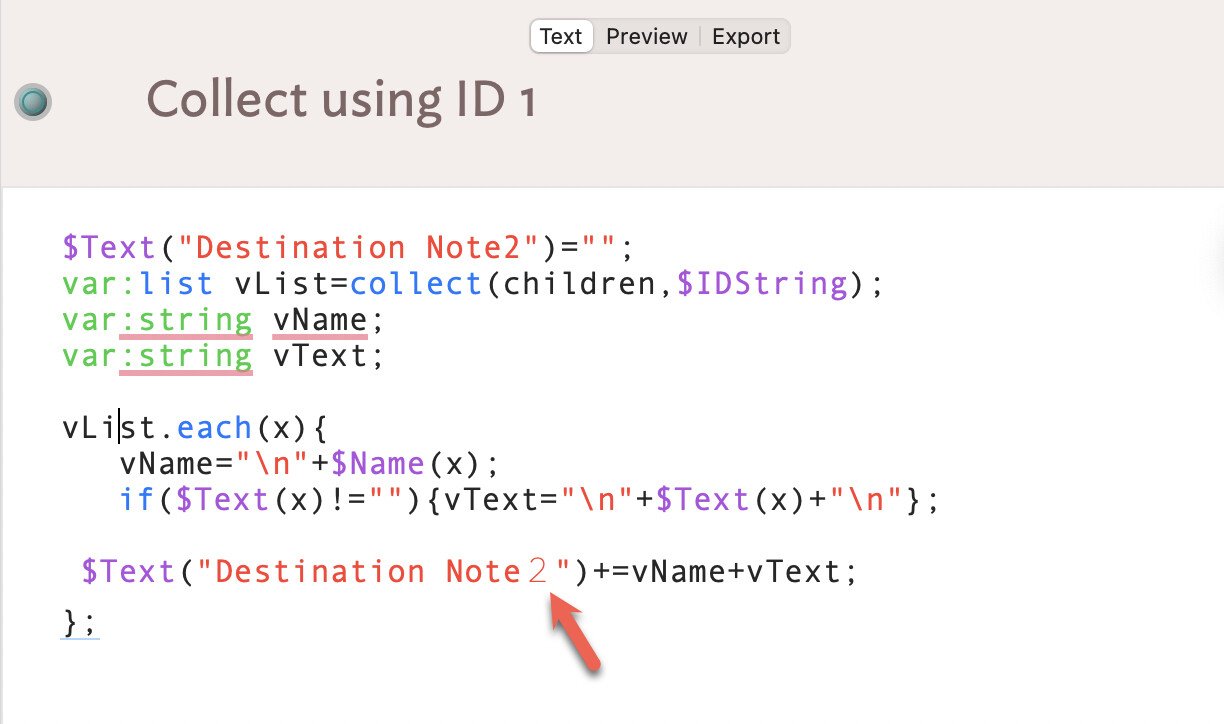
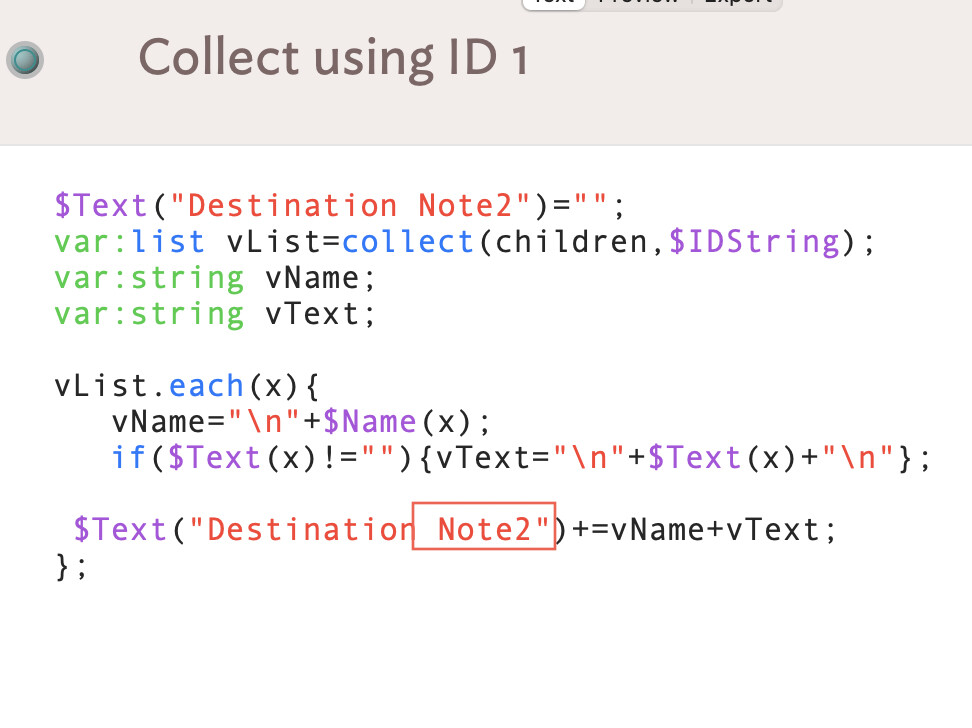
I then went back and tried resetting the margins, font, and text again from the Format menu. This time the cause become more aparant, there is something different about the encoding of the 2"). It is not clear to me why this difference only appears after resetting margins and not the font and size.
This isn’t a Tinderbox encoding error, but the fact the second instance of ‘2’ is using an unusual glyph for that character. Think of it like a normal space character and a non-breaking pace character. To the eye, both are ‘a space’ but to the code they are different characters. Thus when doing a match they are different.
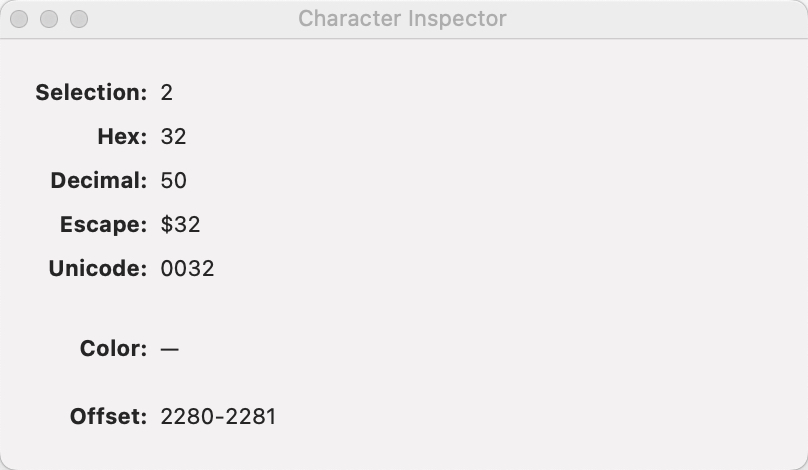
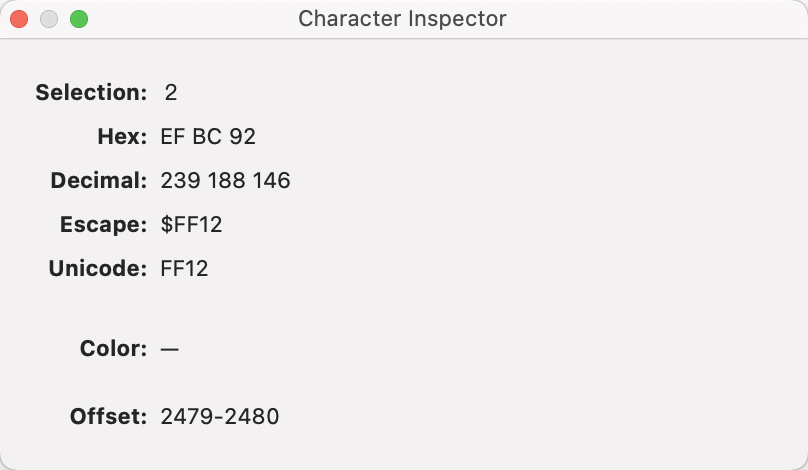
I copied the text of stamp “Collect using ID 1” from “TBX L - CollectChildrenText Becker R2.tbx” to BBEdit:
The first is what we would expect: Unicode #0032. The second gives a different code #FF12 which is Unicode character “FULLWIDTH DIGIT TWO”.
Why the second character isn’t #0032 I’ve no idea , but as this file is being used on both US and Japanese locale Macs, I’ve a hunch the latter might be how a JA locale and/or font might insert a ‘Western’ number two.
So an encoding error, but perhaps not in the way imagined. Thus this is actually a user error—albeit accidental—and not a bug in the app.
Yes, this is my question of encoding. How did it get there? Why did it not change when I tried to reset the font, text, and margins? What can be done to help someone visually see these instances?
Because none of those change the character being used. In a nutshell you have two characters that look visually like a ‘2’ but rare produced using different characters. A decent font (or typeface) will include both characters.
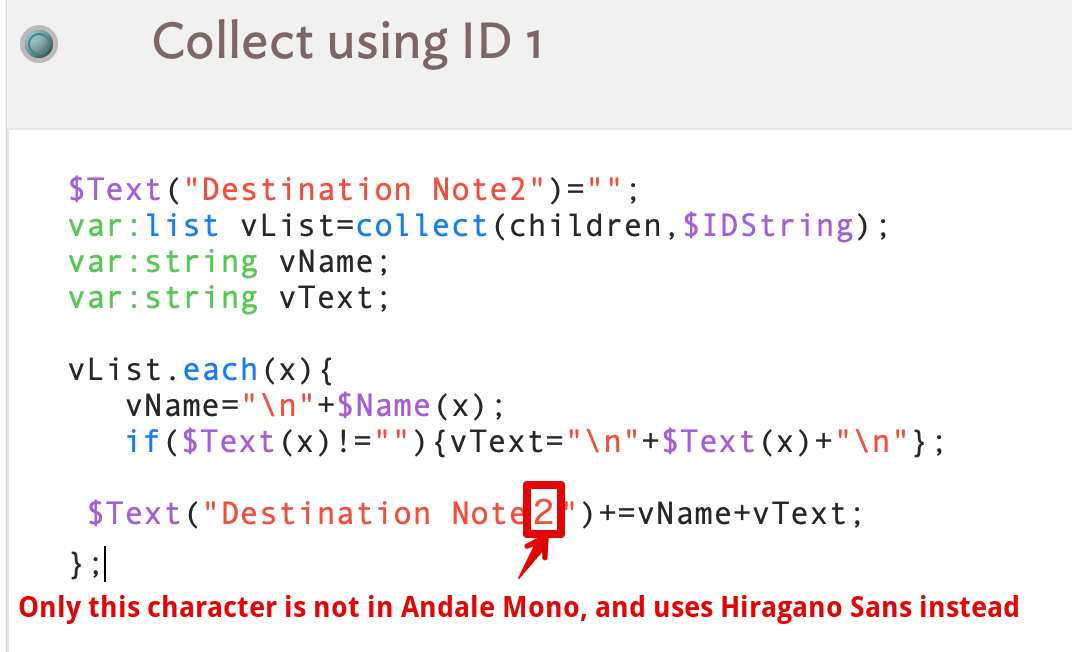
A separate question is why use character “FULLWIDTH DIGIT TWO”? I think my guess (above) is quite likely. Some East Asian languages don’t use Roman-style glyphs for numbers. In Japanese (according to Google) ‘2’ is ‘二’ . Fonts for Japanese might also need to hold a ‘2’ character, but kerning and such (i.e. Wester-style proportional spacing of letters) might not work. Indeed, using my trusty Unicode Checker I see only fonts for Asian language use seem to contain that character. Indeed, in your TBX if I select the second ‘2’ and use the OS Fonts palette, that character (only) uses ‘Hiragano Sans W3’ whilst the rest of the action’s text is using ‘Andale Mono Regular’. The Andale Mono font doesn’t include a character for Unicode point #FF12, so a font that does (e.g. Hiragano) is used instead. How that choice/substitution occurs is beyond me.
There maybe libraries that map #0032 and #FF12 was ‘meaning’ the same thing—i.e. the number ‘2’—but I suspect the problem is less clear-cut than imagined.
So, if we have to apportion blame (I’d suggest not) this is actually user error and not a bug. IOW, if you mean ‘2’ use ‘2’ and not a different character that looks like ‘2’. Don’t forget your demo’s stamp code will have been opened/run on a Japanese locale OS and that is possibly where the ‘wrong’ 2 got used.
Fonts/typefaces are something we don’t generally bother about until we need to.
BTW, to open the BBEdit Character Palette use Window menu ▸ Palettes ▸ Character Inspector.
Agree. I’ve dug in a bit here as the general scenario—two or more characters which look the same—is very confusing. The Os substituting a font if the intended one doesn’t have that character just adds to the fun.
Dear Dr. Mark Anderson and Mr.Michael Becker,
Thanks a lot for your detailed search.
My personal opinion is to use UNICODE as much as possible.
I try not to use Hiragano Sans W3 etc. as much as possible.
The overall font style is Helvetica (I also lived in Switzerland for 6 years)
Generally speaking, I like to use the “Times” font, but some apps have specific font settings, so
Spacemacs uses the default font.
I was looking at the whole thing, and the strange behavior this time was
due to a number entry error on my part.
Regarding “1” as pointed out by Dr. Anderson,
the most frequently used number in Japan is Western European style “1”.
The kanji numeral ”one”(一), which I love, is hardly used today
among the general public.
The tendency of use of original Japanese-style numbers become extremely low.
Personally, I feel very disappointed.
I tried to deepen my understanding by searching the following sites,
but I could not understand it well.
Sincerely,WAKAMATSU
P.S.
(基本ラテン文字 (Unicodeのブロック) - Wikipedia
U+0032 2 Digit Two 2
fullwidth digit two
(2 - fullwidth digit two (u+FF12) copy and paste - Unicode® symbol)
U+FF12 copy and paste
This code point first appeared in version 1.1 of the Unicode® Standard and belongs to the “Halfwidth and Fullwidth Forms” block which goes from 0xFF01 to 0xFFEE.
You can safely add this character in your html code with the entity: 2
There are alternative spelling that can be found in the wild for the unicode character
FF12 like u FF12, (u+FF12) or u +FF12. You can also find u-FF12, u*FF12, un+FF12, uFF12, u=FF12 or c+FF12. You can also spell it with u FF12 unicode, u plus FF12, uncode FF12 or unicode + FF12.
Its bidirectional class is “EN”:European Number
(European digits, Eastern Arabic-Indic digits, …)
If you select that single character and use the OS Fonts palette to set it to Andale Mono, it is now shown as PingFang SC Regular font. Why? Most likely Andale Mono has no glyph defined for Unicode point FF12 so some (OS internal font mapping process) selects a font that does have that glyph.
In other words when mixing English and East Asian languages a paste may result in (unseen) use of an unexpected font if the desired font does not support all characters supplied.
So there is no error in Tinderbox here. But, care needs to be taken when using roman numbers (0-9) in non-roman text. I’m not expert here but I suspect (some?) fonts for Japanese use the fixed-width numbers rather than normal roman numbers, thus for a ‘2’ using Unicode FF12 instead of 0002. Why? I’ve no idea. I stress, no one is at fault here. We are just seeing unexpected results as the OS tries to understand the user’s intent, and getting it wrong.