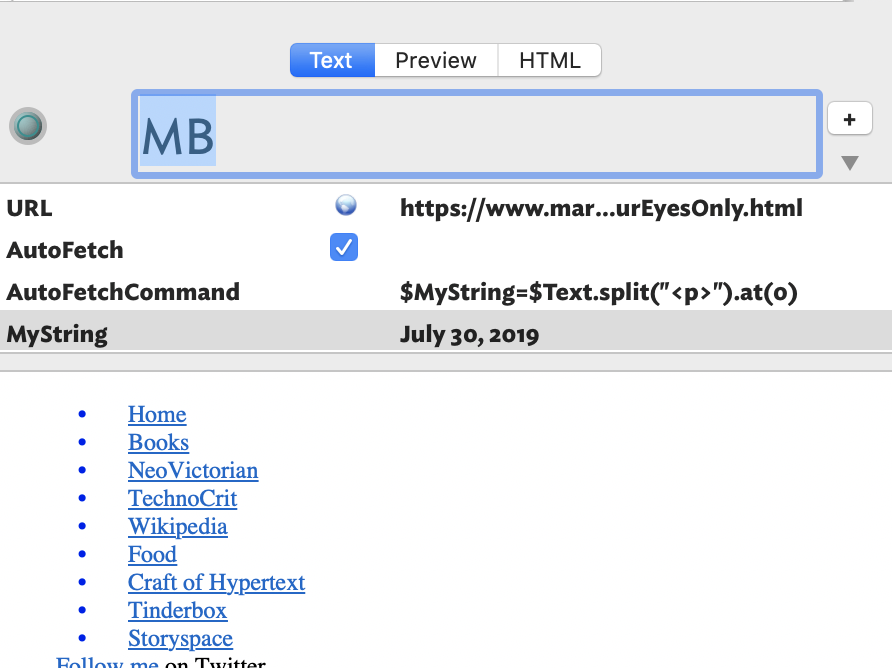
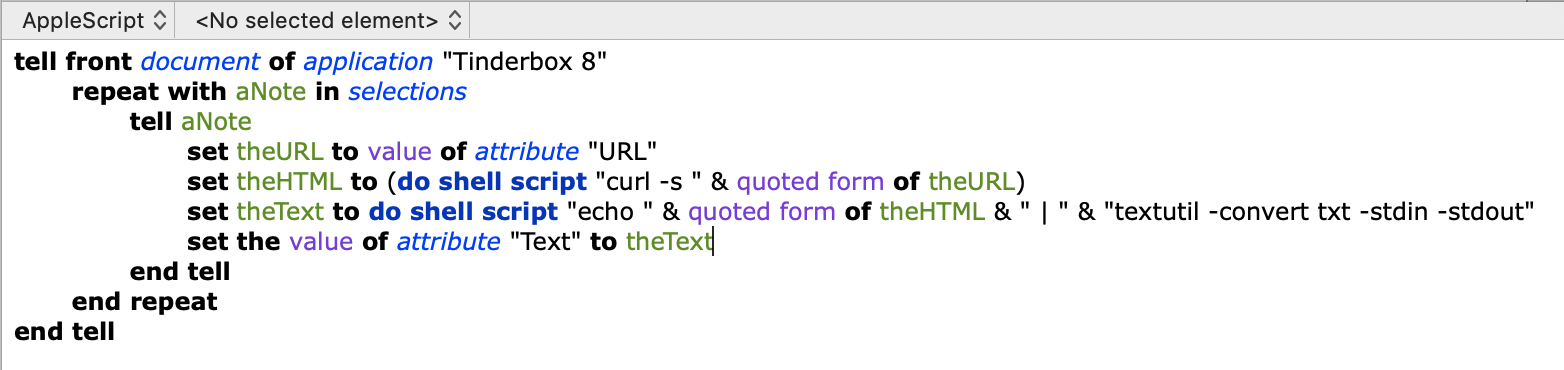
I want to $AutoFetch the contents of a web page at $URL, and I’ve assumed I could use $AutoFetchCommand to post-process the fetched data and replaced the fetched $Text using some sort of command-line driven text simplification utility. (Maybe Pandoc? Not sure.)
I’m not clear on the operation of $AutoFetchCommand. The examples at aTbRef are confusing. E.g, an example that the command in $AutoFetchCommand would replace $Text with the list of files in ~/Documents. Why would someone fetch text from a website and then have Tinderbox replace that text with a file list? I want to operate on the fetched $Text – and replace the fetched $Text with the output of some simplificaiton utility. I don’t want to eliminate $Text, like the examples suggest.
Anyway, I need some pointers to find a command line or web-based “web site simplification” utility, and then how to make that work to clean up a page at $URL fetched when $AutoFetch is true. It allow looks possible, but the exact sequence of events eludes me.
(This is going to be baked into a prototype for notes created by dragging .weblocs to a Tinderbox document.)