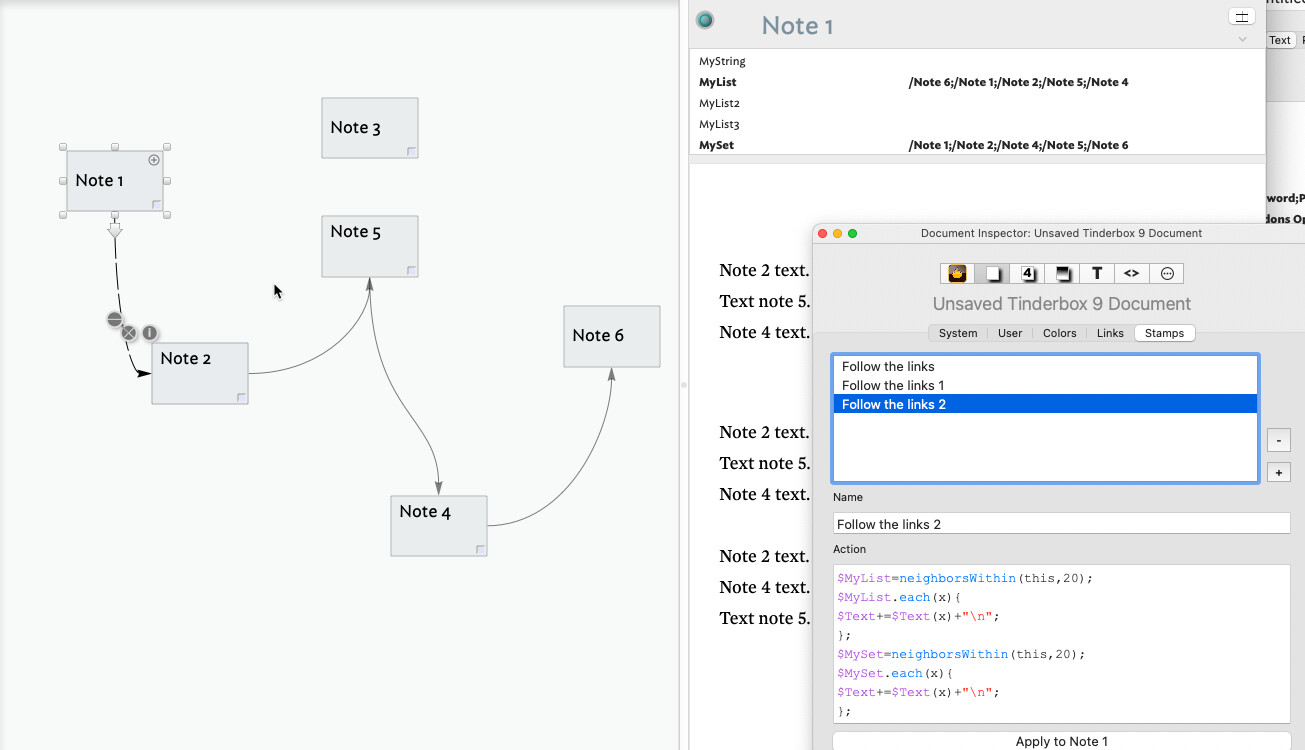
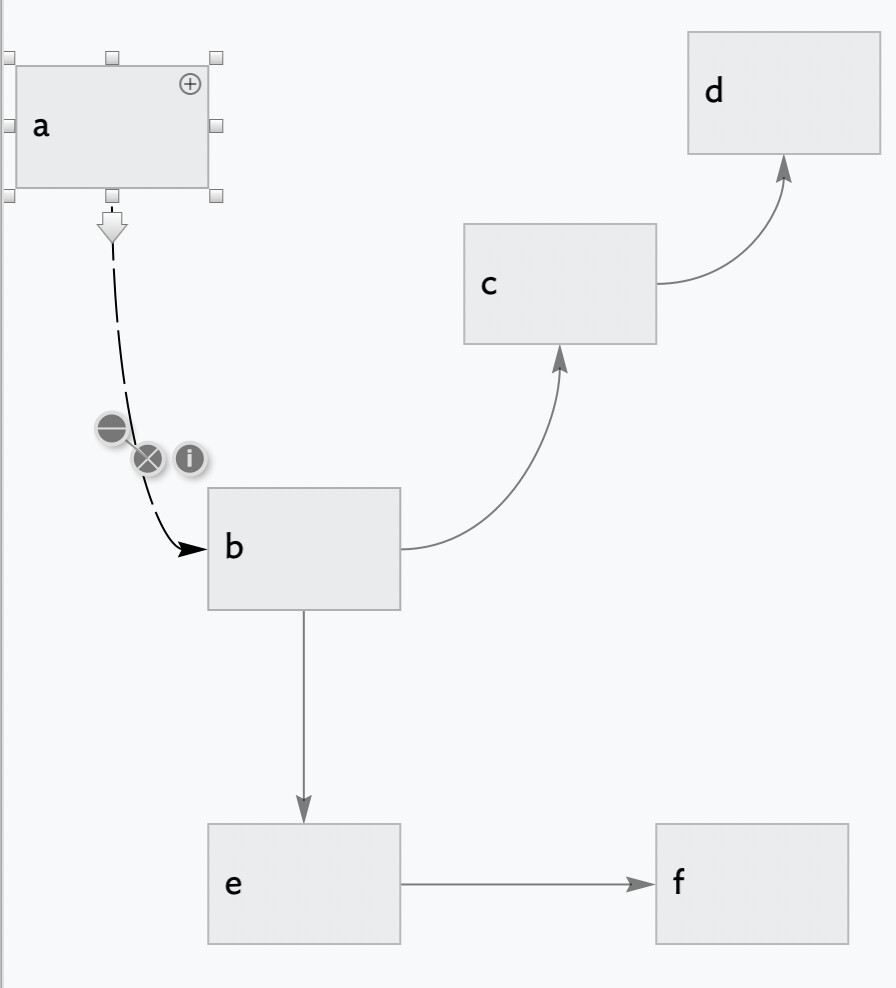
We are curious, we are trying to retrieve links to the notes starting with Note 1 in the exact order of the path the links happen, but we can’ figure out how to do this. When we use $MySet they seem to get returned in any order, and we use MyList we’re getting a different order. We can’t seem to figure out the causation. What we expect is the list to return Note 2, Note 5, Note 4, and then Note 6, in this order. any way to make this happen?
Remember: sets are free too order and reorder themselves however they like. Sets are fast at telling you whether or not an element is already in a set, but they’re entitled to sort themselves.
So, $MyList=neighborsWithin(this,20) is what might work. But, internally, the neighbors operators use sets to decide what to do next and to track what has been done. So, they don’t tell you the order in which they evaluate things.
In the general case, preserving that order doesn’t help a lot:
For each outbound link:
3.1 If the $Distance of the destination is zero, set it to $Distance(this) +1
3.2 Repeat step 3, using the destination in place of “this”
Now, collect the notes with $Distance>0, and sort them by increasing Distance
I got it! Thanks. This works great. Here is the test file I built. This will follow the paths and populate a note called Drafts with the text from the specified/selected note and all outbound notes from the note
Normally would not post this here (and may be moved) but I had a query that is related. I am trying to build a life-list for reading (just retired yesterday!). All the books I would like to read in the order I think they need to be approached. List of books is fairly straightforward of course, but order was not (and of course, they could be ordered as nested sets, but I don’t want that level of hierarchy). Is this the “best” answer to that problem? Unrelatedly, have their been any other posts about such life lists? I remember many years ago Mark B. writing about chapbooks. May have even been in the Squirrel days.
The short answer is maybe. It really depends on what you want to want to do. I’ve not fully wrapped my head around how I’d use this just yet. It was an interesting problem to solve and we (@dtubb, @mwra, @eastgate) solved it. For me, it was a solution without a problem. Perhaps others can find practical uses case for it. @dtubb has one, but I’ll admit I’ve not fully grasped it yet.
I had visualized something like this in map view without knowing how to implement linked order. So, start with Odyssey, proceed to Ovid, Virgil, Dante, for example how to preserve that order. And then Dante branches to many others, etc. Worth thinking about.
In truth I see little linkage here beyond the issue of order (and I don’t mean that unkindly).
If you don’t yet know the order, the above is little help. In fact, I’d suggest you’re addressing the wrong part of the overall problem. Worrying about how to use the order is moot unless/until you have an order and an understanding of how to create it.
If you were to link the items along a single path with no branching, then the above might help in the later stages.
As regards the order, what criteria are you using. Have you attributes to hold/query that data so as to help you generate the order for latter use with the reading?
Mark, first of all do you ever sleep? But you are right. The linkage is partly chronological (Homer precedes Ovid through to Dante) but if it were only that then that would be fine. But the order is in some sense idiosyncratic (I want to read Homer again before tackling Ulysses) but there will be changes as I go through the list. So the ultimate order is in my emergent sense of what I want to read (hence branching that may not always follow chronology or other set-based attributes).
Thanks Michael for digging into this with me! I look forward to grabbing a moment to make this work for my project, and dig into linkPath. When I do, I’ll post with how I use it. It’s for writing in way that lets the structure emerge in the writing.
Reading your reply is useful as I don’t think you necessarily want a fixed ‘order’ as a computer thinks of it (necessarily, precise and binary). Rather, you might want a set of ‘should follow’ as a start point. It strikes me you want on, or possibly, more ‘next’ choices. The exact next might reflect your reading and notes on the most recently read book. The wider your thematic range (i.e. range in/across discrete academic domains or or discrete writing traditions) the more likely, you might flex the immediate next choice. Thus choosing to follow Book X withe discipline A’s take (Book Y) or discipline B’s take (Book Z~) might depend on your feelings rolling out of Book A. Or you might even put Book A aside deciding to finish it (or re-read parts of it) after some other book.
This seems the initially loose incremental formalisation—i.e.delayed/flexible (re-) ordering—task at which Tinderbox excels. This is retirement: the progress is your pace, not some course assessment deadline.
So, the parts emerging is that for a book (aside from ref-type author/date/pubYear, etc.) we might want to know so other things. And, these we state in no particular order/weighting as the all contribute when/if needed to the ‘what book next?’
has the book been read
does the book need re-reading in whole/part:
relating to which book(s)?
what books must this follow:
why? Just date, or due to implicit ‘conversation’ (being critique or agreement) between the different books/authors)
reason book is in list—might be a list rather than a single reason
a ‘should follow’. IOW this books should ideally be read next/soon after [other book]
read with. Some folk like to read multiple books at once, even if with differing speed/close focus. this also links to re-reading as well. Not all books are a simple one-pass
annotation data. This is likely several different things (attributes). We read Book X, but did we record anything. Do we need to? But perhaps after reading/revisiting [some other book]
and so on… we don’t have to be proscriptive before the fact unlike the way much software or processes require.
Or you could just number then 1 through infinity and slog though in fixed order. Tastes vary!
I think there were many good ways to represent the dependencies Prof. Friedland describes in making a reading plan. I see the attraction of nested sets or nested lists, but no — I don’t think that’s ideal.
One approach might be to use the hierarchy. For example, if you wanted to read a bunch of books about Hamlet, you’d probably reread the play first and then read the criticism. That sounds like a note on “The Hamlet Project” with a list of books inside. Michael Dirda describes doing this physically — cardboard boxes the accumulate books related to future reviews he wants to write. Probably in Book By Book.
Another approach might be to use a link type that means “readAfter”.
Thanks to both of you. Mark A has precisely captured what I do want to do and these are useful starting points. Mark B also, some of these will likely function as nested sets (so for example all children of Homer: Ovid, Virgil, Dante, Joyce) but of course at any point (e.g. Dante, Joyce) there could be other branches or other prior paths leading to them. So “read after” makes sense too.
Again, thanks to both. Digesting the advice and getting started. Question: what are the practical differences between “next book” as a link and an attribute. Among the things I like about linking: ability to generate maps of dependencies. Attribute seems more powerful in search. (Suspect I’m wrong
My experience is links get used in two quite discrete ways. The most common is in Map view, where a visible link is drawn between notes to indicate connections or dependencies. A corollary is that the link type is use as a visual label of link intent.
The other, richer, form is using links (very often not in Map-centric use) where the the link type is used for signalling the semantic intent completely disconnected from whether the link is ever drawn on screen.
Neither is ‘better’. That is a false comparison, but it does call one to question personal workflow.
If one is of the ilk of those who think “can’t the computer just tell me?”, then copy a list from the web or a book and march the list. This is not wrong if it is what you want.
My earlier answer spoke to a more considered approach. Which circles back to your question:
Actually, and not judgmentally, I do think you are wrong but only because you make these a false binary. We are only the prisoner of our false assumptions. For instance if I ‘think’ in terms of a a map how else can I show dependencies except linking parents to children. An outline has no such dependency. However, as my post up-thread suggested, the real value is in more nuanced thinking: how does book X relate to book Y and why—in terms of a putative reading order. For that attributes are probably your start. After that you may choose to add links etc, though I think links are inadequate at capturing such nuance in the initial analysis .(and I’m happy to be wrong!).
It is also important to clarify if we are reading a canon where little if any choice exists as to order, or whether the order is less fixed (for any of a host of reasons).
I saw , sadly I forget where, someone describe a book pre-review process, where they started by looking at each book with an aim to figure the time-to-read needed to read it. A book’s page count is a poor guide as in a scholarly monograph the endnotes may be a significant proportion of the page count. Annotating the chapter page counts (and perhaps intro and epilogue) can give a better insight into the effort/time needs: not everyone has all day to read.