Is there a way to isolate, find, or collect text with particular formatting?
That is, suppose I want to create a note or container that collects all the boldfaced text from some notes. Is that possible?
Thank you.
Is there a way to isolate, find, or collect text with particular formatting?
That is, suppose I want to create a note or container that collects all the boldfaced text from some notes. Is that possible?
Thank you.
Although there is action code to set bolding on a string, is is not a searchable feature. But, have you considered AppleScript? Probably better researched in an AppleScript centric forum, but I’d be surprised if it wasn’t possible.
Thank you for the swift reply. I’m a newbie, so perhaps there’s a better way of doing what I want. I’m creating many reading notes, with text ranging from a few words to a few hundred. Within those notes, there are portions that I want to collect elsewhere, because they have special significance. My first thought was to highlight them by marking them bold, but there are other possibilities. I could bracket these passages with %%special characters%% maybe. The goal is to have a special note with $Text composed of these snippets, concatenated. Does this make sense as a plausible problem?
Yes, marking the text rather than styling it would make to possible to match section(s) of a $Text using .contains() and using the back-reference created by the regular expression to pass the matched string to the end of $Text in another note. In designing your workflow, you will need to consider how/where you will record a note has been checked so you don’t keep re-adding the quotes.
Yup, as Mark points out, there are a ton of great methods for this. You search for notes with those juicy bits with agents, you can extract the juicy bit with action code (e.g. the new .following action code is perfect for this) and then put the extract code in a new note or an attribute. Using icontains() you can look for keywords or special marketers, e.g. ## or kwd:. If you provide a bit more detail about what you want to do (e.g. search for notes that have the target text, or create a new note for the target text, or populate an attribute with the target text) we can create an example for you.
Certainly putting markers (e.g. %% like @gleick described) both before and after is very useful if you want to extract runs of text that aren’t a whole paragraph or line. I Choosing such markers pay especial attention that the marker sequence:
% is sometimes use as an escape symbol for comments in code.So, it is hard to give a one size fits all solution, but of the above, the first is the most important. By trial and error I find #### is fairly safe. A longer marker string lessens the chance of bullet #2 above occurring but if the markers have to live in your document they will make the $Text less readable if there are many such markers.
The wider learning point for other Tinderbox users here is what to do when finding a method you’ve used elsewhere—on paper, in another app—doesn’t seem to work. Having looked at the docs asking here, as in this thread is good. Having then ascertained that text visual styling can’t be queried by action code, it is time to re-think the strategy. Above, we are looking at placing markers in $Text so regex actions can find and copy the quotes. Another approach might be to make the quotes text-links to the reference note. Indeed using the zip-links method (with optional back links) might work, though that probably needs trying—I’m a bit to busy to take that test on now.
Below is a simple AppleScript to collect all bits of text that have italic formatting. It takes advantage of Tinderbox’s built-in html export capabilities. (I used italic because bold export seems to be broken in Tinderbox 9.0. No markup in the html. )
run button in Script Editor. The results will be placed on the clipboard for pasting wherever.(If “nothing happens” make sure Script Editor is listed and checked at System Preferences > Security & Privacy > Privacy > Accessibility.)
The script:
-- get the Tinderbox export html -- italic will be within <i> </i> tags.
tell front document of application "Tinderbox 9"
if not (exists selection 1) then error "Select the container and run again"
tell selection 1 to set htmlStr to evaluate it with "exportedString(this,$HTMLExportTemplate)"
end tell
-- "chunk" the text to isolate the italic bits
set text item delimiters to {"<i>", "</i>"}
set textItems to text items of htmlStr
-- gather the even chunks (the italic items) into an AppleScript list
set italicItems to {}
repeat with i from 2 to length of textItems by 2
set end of italicItems to item i of textItems
end repeat
-- convert the AppleScript list to text and place on clipboard
set text item delimiters to return
set theExcerpts to italicItems as text
set the clipboard to theExcerpts
return theExcerpts -- to view in results panel
This is HTML from a quick test in a new v9 TBX using v9 default settings:
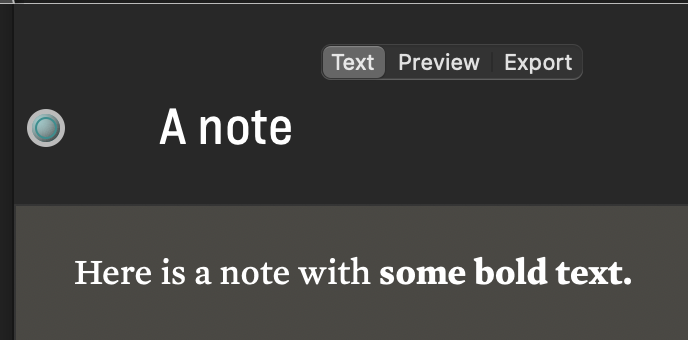
<h1>A note</h1>
<p>This is <i>some</i> text.</p>
<p>Another <b>run</b> of text.</p>
The code is taken from the HTML export pane. I get the same if I use this action:
$Text = exportedString("A note",$HTMLExportTemplate);
I’d check:
<b> and </b> respectively.I assume the above, for bold becomes:
-- "chunk" the text to isolate the bold bits
set text item delimiters to {"<b>", "</b>"}
set textItems to text items of htmlStr
(Sorry no idea why the markdown code formatting is rendering different from above (it’s using the same mark-up of 3 back-ticks on the lines before/after the code).
Yes that should work well with bold!
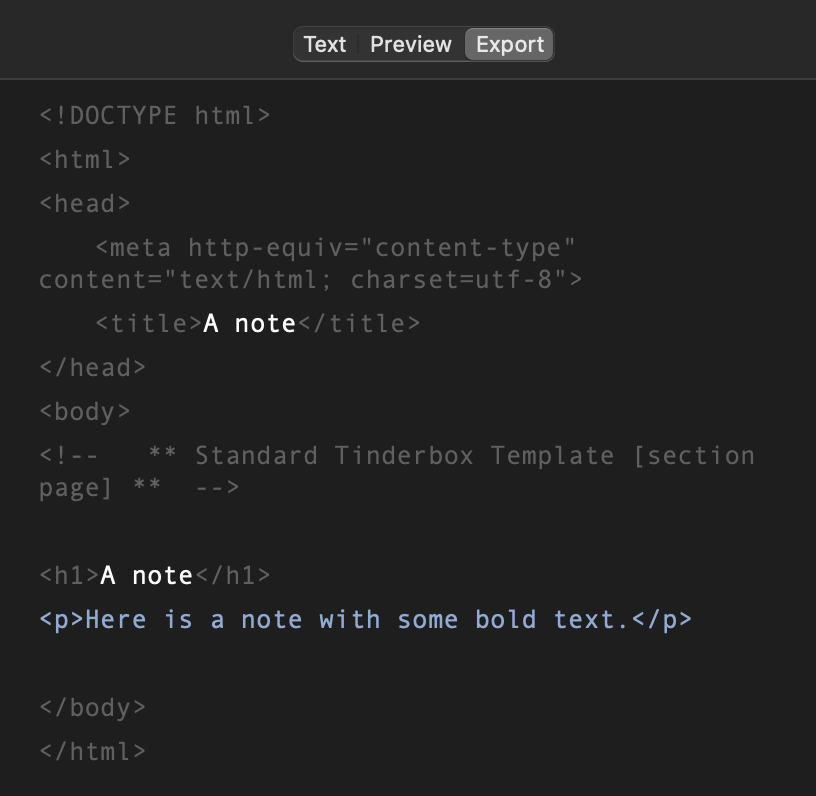
However, I’m not getting bold mark-up.
Here is a sample TB document showing the problem on my end.
Sample no bold.tbx (83.3 KB)
All I did was…
Here is your file for me:
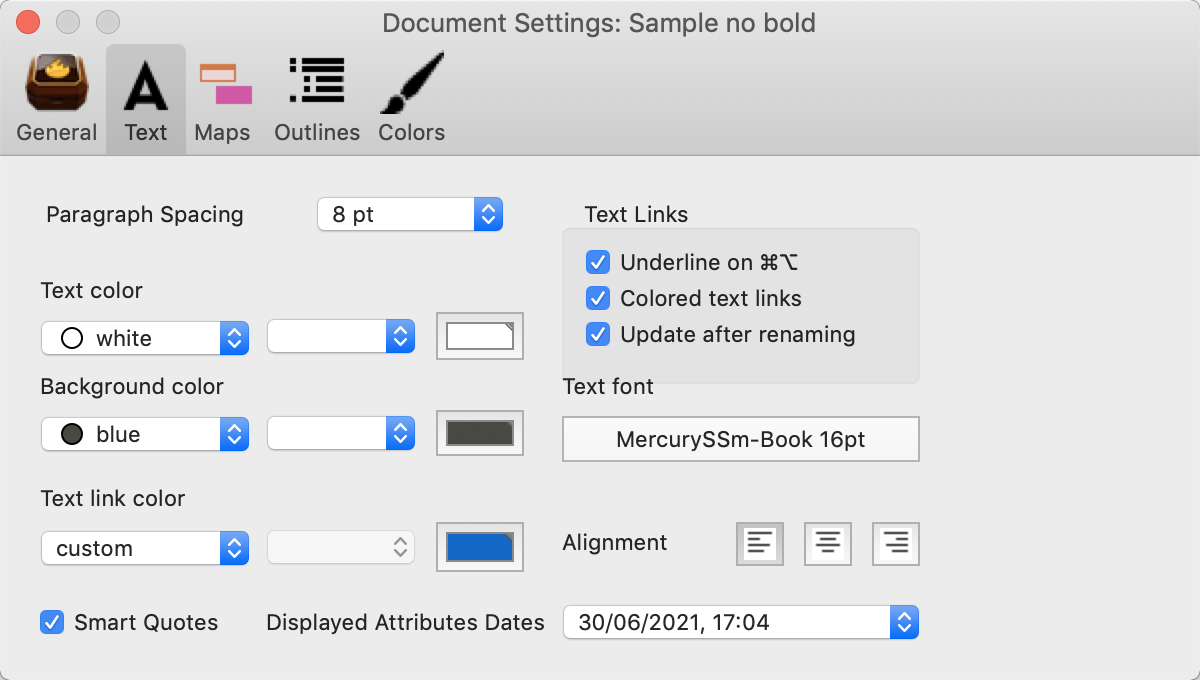
A thought - I’m still on macOs 10.14.6. If the files’s style attribute settings are correct (they are in your text file) I wonder if this is an OS-related issue. I assume Tinderbox is parsing the RTF internally for use of a bold variant of a typeface and using that for bold sections. Perhaps something in the way Apple frameworks parse this in different OSs is an issue?
That’s possible. I’m running Big Sur 11.4.
Is the font in a Tinderbox document the same when opened on different machines? I assume this one is the default in Tinderbox 9?
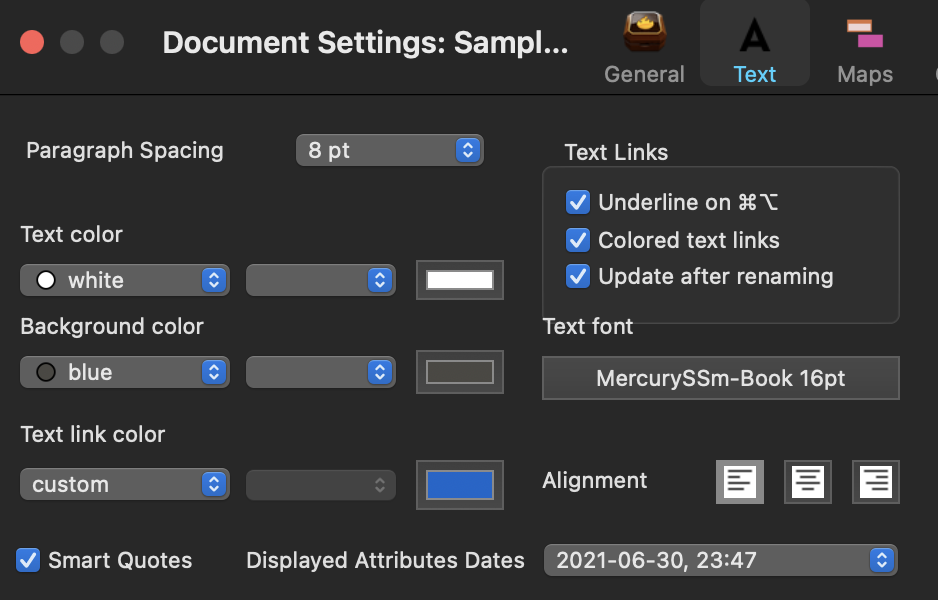
Here’s your same doc’s Doc setting on my 10.14.6 system:
Same except my UK (locale-derived) date styling.
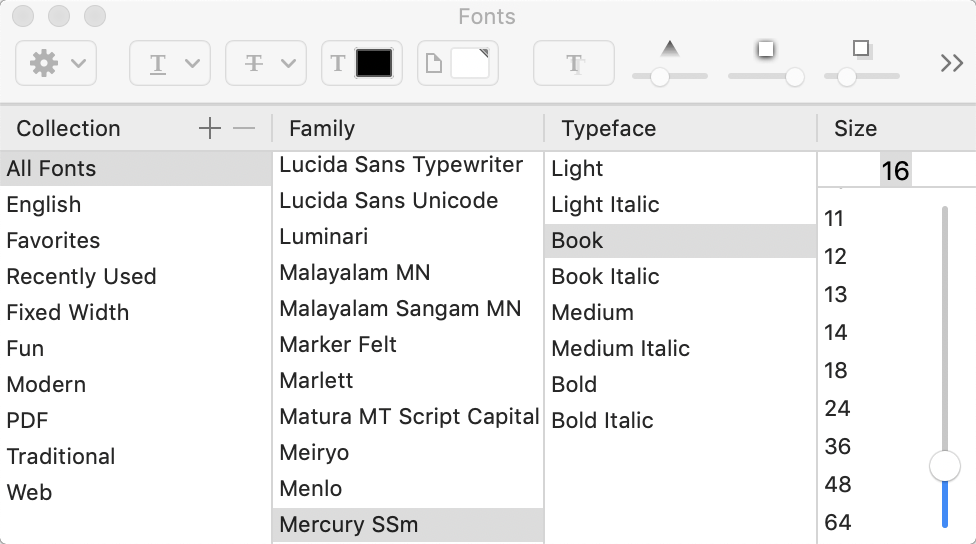
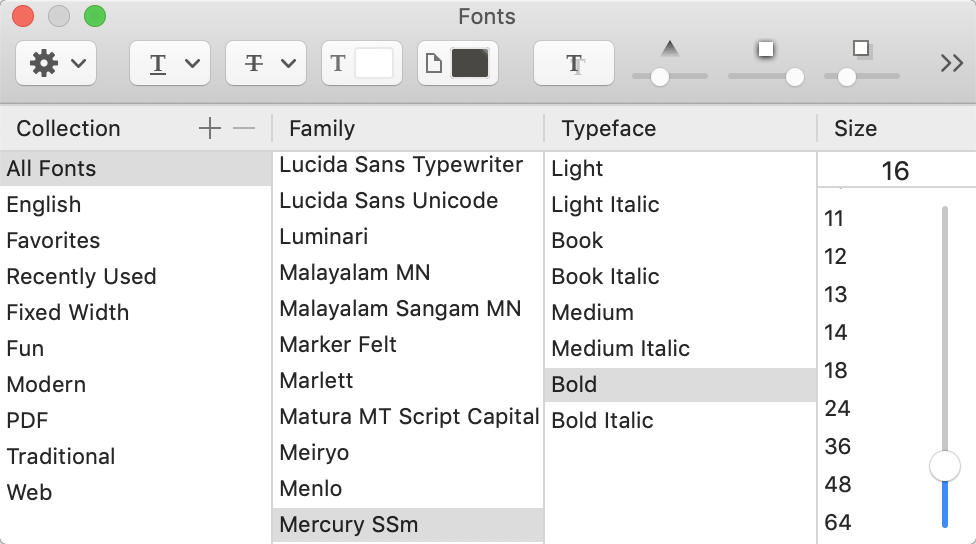
Opening the Fonts dialog via the ‘Text font’ button, I see:
Testing with your specimen export note, and the same Fonts dialog, then placing the $Text cursor in some bolded text shows as using ‘Mercury SSm Bold’.
FWIW, italic text uses ‘Mercury SSm Book Italic’.
Anyway, Ive reported this via a thread on the Backstage forum, referring back to this thread.
Ok, great. FWIW, I opened the same document in Tinderbox 8.9.2. and the bold isn’t marked up there either in the HTML pane.
Meanwhile, italic seems to work reliably for simple styling and extraction without getting involved in manual text markup codes, etc…
Thank you for this. I see how to use regex to populate an attribute with “the juicy bit” (text between my special markers). But I’m only getting the first juicy bit. What if there are multiple juicy bits, each set off with the same markers?
I assume you are using String.contains()—or icontains—these only pass back the offset of the first match.
I’d suggest the AppleScript approach is probably better.
The is no simple way of asking Tinderbox to pass you all instances of sections of $Text between two markers. For a start you actually mean between every odd and even numbered instance of the marks. IOW, text between marker 1 &marker 2, 3 & 4, etc. but not the text between markers 2 & 3.
At this point I’d re-think my annotation strategy, at least for future annotation, as you’re essentially relying on a non-existent feature.
Or, perhaps not-yet. (I think this idea of extracting highlighted parts of notes makes sense.)
@gleick What if there are multiple juicy bits, each set off with the same markers?
It turns out that with runCommand and egrep Tinderbox can quite easily extract multiple instances of text between two markers.
Here is a demo file:
Excerpts demo.tbx (92.1 KB)
The action code in the stamps is like this:
// specify starting and ending markers -- must be different //
var startmarker="<i>";var endmarker="</i>";
// put marked up Tinderbox export string into a variable //
var str=exportedString(this,$HTMLExportTemplate);
// use regex in egrep to extract matches -- each will appear on a separate line //
$Text=$Text+"EXCERPTS \n"+runCommand("egrep -o " + "'"+ startmarker +".+"+endmarker+"'",str);
// remove starting and ending markers -- do longer one first //
$Text=$Text.replace(endmarker,"").replace(startmarker,"");
Select the container folder containing marked up notes and run a stamp. The excerpts from the children notes will be placed in the text of the container note. The stamps can also be run on an individual note, in which case the excerpts will be appended to the existing text of that note.
startmarker and endmarker can be changed as needed. In the demo file I’ve tried italics, bold, and arbitrary starting marker of && ending marker of &&&. I find it much easier to select text and hit command-i (or command-b) than insert special markers.
This is more concise than the AppleScript upthread. But it was much fussier to debug. Plus AppleScript can be placed in the Script Menu and easily reused with other Tinderbox files without messing around with copying stamps, etc. AppleScript deserves more respect around here. ![]()
Both approaches require the built-in HTML template to be present (File > Built-in Templates > HTML).
And here is a cleaned up AppleScript that does the same thing, except it places the result on the clipboard instead of in a note:
-- specify the html tags that match the styling
set startingMarker to "<i>"
set endingMarker to "</i>"
-- for bold use <b> and </b>
-- can also use arbitrary markers unrelated to styling
-- startingMarker and endingMarker must be different from each other
-- get the Tinderbox export html
tell front document of application "Tinderbox 9"
if not (exists selection 1) then error "Select the container and run again"
tell selection 1 to set htmlStr to evaluate it with "exportedString(this,$HTMLExportTemplate)"
end tell
-- "chunk" the text to isolate the parts enclosed by the markers
set text item delimiters to {startingMarker, endingMarker}
set textItems to text items of htmlStr
-- gather the even items (those are the ones enclosed in the markers) into an AppleScript list
set extractedItems to {}
repeat with i from 2 to length of textItems by 2
set end of extractedItems to item i of textItems
end repeat
-- convert the AppleScript list to text and place on clipboard
set text item delimiters to return
set theExcerpts to extractedItems as text
set the clipboard to theExcerpts
return theExcerpts -- to view in results panel
You are amazing. This is SOOOO cool. ![]()