@webline does this work in the backstage releases yet?
don’t know - I have no access to the backstage version - but Tom told me it doesn’t do it. The JSON parser in TBX seems to have changed.
There is no bug! Backstage users are advised to always read per-build release notes, qv those for build 611. Details of this should be discussed on the separate Backstage forum.
The background here is a change (Backstage only until the next public release) to JSON parsing operators. A new improved JSON operator replaces .json() and the latter is no longer supported. Code using he latter will need to be updated.
So those running the current backstage releases >b611 will need to update all code use of .json().
Agreed, no bug. Nothing is “wrong” per se, just part of the on-going learning exploration. ![]()
I’m fine with it - I will adjust the code if the new version is public. It’s only a problem if users try my demo with the beta…
using the text of the note “myJSON12_raw” in the demo here are some examples of prompts you could use with OpenAI in Tinderbox:
- Extract not more then 15 of the most significant keywords from this text as comma seperated values
arcades project;future generations;ideas;important;lifetime;long-term memory;longevity;luhmann;notes;reading;scientific literature;structures;thoughts;transcend time;zettelkasten
- find relevant scientific literature related to the following text and return the titles as comma seperated list
“a study in scarlet” by sir arthur conan doyle;“on the art of reading” by arthur schopenhauer;“remembering: a study in experimental and social psychology” by frederic charles bartlett;“the arcades project” by walter benjamin;“the collective memory reader” edited by jeffrey k. olick;and daniel levy;vered vinitzky-seroussi
- Create a comma separated list with all proper names in the following text
arcades project;lifetime;longevity;luhmann;walter benjamin;zettelkasten
- Create a comma separated list with all nouns in the following text
arcades project;battle;benefits;companion;comrade;distinction;endeavor;generations;goal;ideas;knowledge;lifetime;literature;longevity;major;memory;note;thoughts;work;zettelkasten
With other text samples…
- Create a comma separated list of word frequency for the included keywords
ausgeschlossensein: 1;autorin: 7;autorschaft: 1;diskurs: 1;eigenständige: 1;frauen: 3;frauenbilder: 2;gesellschaftliche themen: 1;kulturelle ordnung: 1;kulturgeschichte: 1;literatur: 1;männlich: 4;normen: 1;objekt: 2;ort: 2;patriarchat: 1;rollenzuweisungen: 1;selbstbildnis: 1;sigrid: 2;spiegelung: 2;strategie: 1;struktur: 1;subjekt: 1;weibliche: 5;weigel: 4;überhöhung: 1
Any other good ideas?
1 Like
I added a first version to play with the DALL-E model of OpenAI to create an image. The text of the note should describe the image you are looking for. After creating the image it will be downloaded to your desktop. You can adjust the path where the image will be created in the gAIPreferences note.
Just select note myJson12_raw and the apply the stamp CreateImageFromNote and Tinderbox will create an image for you.
Like this one: “a photo of a mouse jumping, like painted by Andy Warhol”

OpenAI-Demo_Keywords_image.tbx (254.2 KB)
P.S.: OpenAI charges $0.020 / image in 1024x1024 pixels
This is so cool!!!
This is: “Michael Becker, Warhole style” ![]()

but I will stay with the text models - there is much room for improvements.
A great improvement (-> new feature) for TBX would be the support of Apples ML models. There is an app called “CreateML” (part of Xcode) that helps to train your own ML model.
Two years ago I used it to identify watersigns in medieval handwritings - worked very good:

This is a very different approach from using OpenAI and very powerful. If TBX would integrate the Core ML engine in way that we could use our own models… incredible ![]()
2 Likes
I did some experiments with this. The language part of CoreML is thinly used at that time, which made things difficult, and the training requirements seemed daunting. But it was easy enough to do…
1 Like
Hm, having met IRL the person supposedly pictured, I’m totally underwhelmed by the result of the above (the style is immaterial). Just because AI gives gives a result, it does mean there is a sensible result. ‘AI’ seems to have stopped us asking if the results even make sense, a useful habit humans have acquired ver centuries if not more.
I’m not trying to be rude about the process here—in terms of interfacing Tinderbox to AI. But, in all seriousness automated crud is still crud, just delivered to you more quickly (by AI) and without a warning as to quality. On a closed track with a trained driver, AI can give OK results but in the wider context I have trust issues.
TL;DR: getting AI output != sensible result.
1 Like
I don’t think AI can or will change our behavior in the short term. Even without AI, we believe what we want to believe. Reportedly, only 18% of Brexit supporters are still positive about the outcome. But well over 50% of this group believe it will get better. That’s without AI (well - almost).
AI is simply a tool and “a fool with a tool is still a fool” certainly applies here as well. Nevertheless, I see exciting prospects here and would evaluate your assessment as too negative. I found the results of DALL-E rather not good. That looks different with the text-based models. But they were also fed with data from Twitter, and a large part of it was probably garbage. Now AI is also to be used to distinguish good content from trash and fake. How will that turn out if the AI itself gets food written by another AI?
But I still like the idea that the basis of AI use in Tinderbox is my notes written by me, so I’m not relying on content that comes 100% from AI. I want to assess, evaluate and add to my content and selected third party content.
If I wanted to understand it as an evolutionary process, Google was the successor of pure hypertext documents and AI is now putting a step on top of Google.
1 Like
As said, I’m not critical of process, just doubting of results. Confirmation bias means we’re overly receptive of things that look right (or even anything from a process we’ve previously considered too hard). Software engineering has a particular blind spot in this regard: result == progress, and progress is generally goo therefore the result is good.
I’m not against LLM-based aI at all, I’m just conscious of societally/culturally blind I am to it’s output quality. I don’t expect honesty from someone selling replacement windows (it’s nice if they are!) but I do expect my doctor to be honest talking about a cancer treatment. A societal problem is we are treating AI as the latter not the former in contexts where that trust is not warranted by results (as in not all output is useful/truthful).
In the case of DALL-E, making pictures of imagined worlds seems reasonable and thought provoking. Using it to make a ‘better’ picture of me for my passport/ID/etc., maybe not so good. But as all we get is ‘output’ how do we tell. I don’t pretend to know the answer but it’s a challenge of the her and now given the way AI boosters oversell its veracity.
I don’t think doing experiments with new tech should stop us pondering on the quality of the output—or stop us doing experiments. The former is not explicit criticism of the latter. ![]()
2 Likes
I’m afraid studies of psychology (and history) would not seem to support the proposition that we have acquired the habit of asking if results make sense – certainly not all of us. And the problem existed well before AI. The Second World War and the attendant Holocaust is merely one example of what can happen when a completely daft idea takes hold among a large number of people.
Dead right. As psychologists have shown, it is not rationality or reason that is the most potent driver of human behaviour. This article from six years ago deals with some of the research into our difficulties with facts – and “facts” … E. Kolbert – Why facts don’t change our minds
Further, Tversky and Kahneman were looking at decision-making fifty years ago, and how biases could influence it. Much of their work is summarised in Kahneman’s book, Thinking, fast and slow.
As to whether AI is going to worsen the situation – well, it wasn’t that good before AI. There have been plenty of conspiracy theories through the centuries, unfortunately. The research that has been done up to the present would seem to show that the human mind is not optimised for using rationality when processing information. Would that it were so, but the evidence for it is not strong.
A further complication, which I believe is worth considering, is that the ways that people think can be influenced by culture, and that there are noticeable differences between western and eastern cultures and societies. This has been extensively studied by Nisbett and associates, for example in Culture and systems of thought: holistic versus analytic cognition. I’m wondering if there will be an “eastern” AI, and how it might differ from a western one. (I assume that ChatGPT is based on western notions of information processing.)
Good luck to us all!
5 Likes
This was actual a question brought up by @ArtRussell last weekend, i.e., wester vs. eastern influence on AI.
ChatGPT seems to be disturbingly good at translating English to Chinese, Chinese to English. So it must have trained on masses of “western” and “eastern” documents. But wait. That assumes modern Chinese is “eastern.” Is that correct? It’s laced with a lot of Marxism these days. Is Marxism “eastern” or “western”?
It is a good bet that Chinese-style ChatGPT like services won’t train on dangerous “western” material that conflicts with (western?) Marxism. Complicated!
Anyway, great to see this discussion and these intriguing efforts to integrate various AI into Tinderbox.
3 Likes
This is an awsome tool. thank you so much for sharing!!
and this is what I got after the OpenAI engine processed the notes:
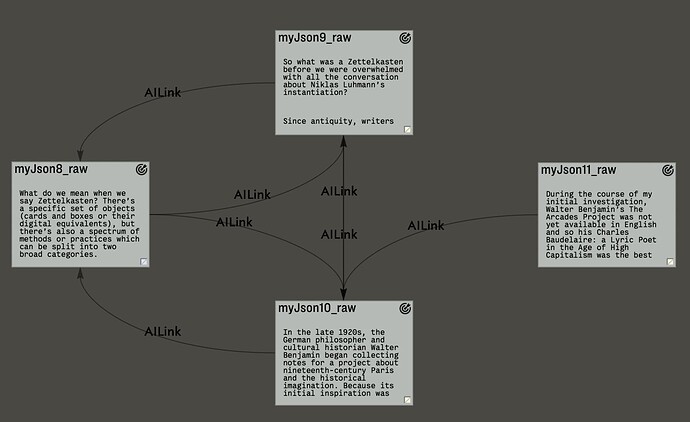
Were the links automatically put in place too? Am I wrong if if I say that it seems they were manually arranged? I mean: has AI got any aesthetic sense?
1 Like
alle links are placed automatically!
FWIW, there is currently no automated method to set the sdie of a note from/to which links attach. The position can be altered manually.
Note: a feature request/suggestion has already been made that the link’s stored attachment position metadata (
sourcepadanddestpad) be made readable/editable viaeachLink().