Qualitative analysis of literature, which 1) automatic linking of notes, 2) dynamically creating excerpts from highlighted notes, 3) using hyperbolic view to assess relationships, and more.
Mark Bernstein introduced a new view
Michael Becker previewed a new “working with media in Tinderbox” template that he is working on
Qualitative Data Analysis of Literature: Alexander Quartet Text
Malcolm MacGarvin (@macgarvin) and Michael Becker (@satikusala) walked us through methods for literature analysis. They used the Alexandria Quartet as the base text. This process and method was adopted by Malcolm from preview meetup training.
Malcolm reviewed the tagging and linking strategies he uses when reviewing text, including a look at the hyperbolic view. This approach can be used for any body of text, including commercial and academic focus group interview analysis and related qualitative data analysis work.
Michael Becker walked Malcolm through the step-by-step approach to use action code to dynamically produce excerpts from highlight text and the team discussed other annotation strategies.
This relatively simple Tinderbox workflow enables the user to perform a customisable analysis (i.e., qualitative analysis) of any text, perhaps your own draft writing, or existing documents, for example, synopses of papers or books, or the entire texts. More than one document can be included.
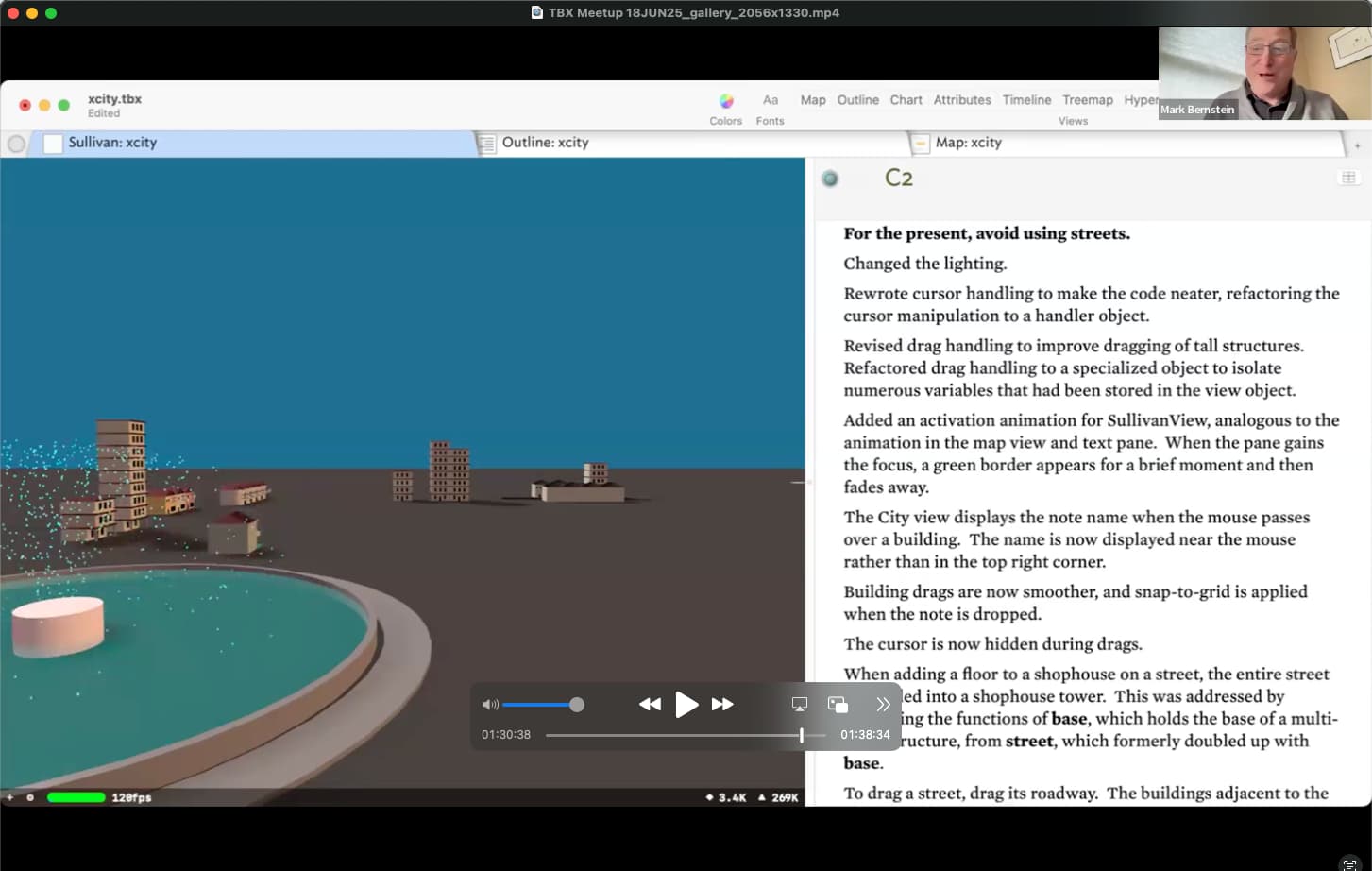
Introduction to a New View (virtual special view of notes: containers look like buildings)
Mark Berstein and a group of collaborators are working on a new virtual speical view for Tinderbox: think Tinderbox comes to a second life. In the view, note containers and their children take on building floors. The goal of the view is to get more information on the screen. This should be fun!
Lately I’ve been a bit busy and haven’t been able to attend the meetups; but I have discovered a great tool at the podwise.ai website - I use it to summarize podcasts, and you can also use it to summarize content on Youtube channels. I’ve attached an outline (done with Xmind) that was created by podwise.ai from the Tinderbox meetup video of 2025-01-18 Tinderbox Meetup, Sat. Jan. 18, 2025 (Video) Analyzing Literature (QDA), Intro to New View.pdf.zip (164.3 KB)
re: the Highlights Yellow & Blue in Malcolm’s example
Let us say that I’ve made a first pass through a document & highlighted terms of interest because I’m unclear what they mean.
I use “term” to mean any of word, phrase, acronym, initialism… a string of characters to which I want to attach meaning.
Let’s pretend I’ve highlighted “International Business Machines”.
Is it feasible to convert that term — consisting of three independent words in a single phrase — into a single term: “International_Business_Machines”?
Im NOT interested in “international,” “business,” or “machines” as single, independent words.
Yes. The entire highlighted string, e.g., “International Business Machines,” will get returned to the attribute. If you’ve highlighted multiple strings, each item will be returned into the list/set.
BTW, you can also install a command line tool to look up definitions and synonyms of terms and have them returned to Tinderbox. I can demo this at the next meetup, if you’d like.
Don’t forget that, if you select or just hover over a word and hit ⌘^-D, you’ll get a popup window with the dictionary and thesaurus for that word. I find this especially helpful in other languages, for which you can install auxiliary dictionaries.
One question for @macgarvin: I think I understood what you were doing with the Tinderbox file and it looks very interesting. But I have a practical question about how you set about populating the basic text.
As I understood it, you have the entire text of the book in the file, and I wondered how you got it in there. I don’t mean how you used Tinderbox to explode the notes once the text was in, for example, but the pre-import stage of getting the text ready to be imported from its original format into Tinderbox. I assume you didn’t type it all in!
E.g. did you OCR the text? I would like to analyse a few books and some details and tips of how you went about it would be very helpful.
Exploding and then the judicious use of Tinderbox operators are the foundational skills needed to get the most out of operators. Copying and posting, use of OCR, drag and drop (e.g., from a csv file, PDF, markdown file, Word File, or reference manager, i.e., any number of ways to get at root text, help you get text into Tinderbox. Once the text is in Tinderbox, you can then use the operators to curate it (i.e., populate attribute values by atomizing its elements and start populating desired attribute values—it helps to remember that $Name and $Text are attributes, just like any other).
I know how to deal with the text once in it’s in Tinderbox via explode and populating attributes via regex etc.
It’s specifically Malcom’s experience with the practicalities of getting large amounts of text out of the books in the first place, given the ridiculously restrictive DRM limitations on Kindle books, for example, where copy and paste isn’t an option. I have tried OCRing individual pages with screenshots, but it’s a tedious process and if he has any better way, I’d be pleased to hear about it.
I suppose I could limit analysis to anything in Project Gutenberg, but the Alexandria Quartet is a bit too modern for that yet…
David, try doing a search to find an open-soruce or related dictionary that has an API. If it does, I can show you how to integrate to the API with Tinderbox.