One thing I use DevonThink for is reading PDF files and highlighting interesting text to be reflected on later (preferably in Tinderbox). My current approach is to export the highlights in tabular format and read this into Tinderbox. It works reasonably well but has some disadvantages which include:
Reading the export in toe Excel and editing the column names to be compatible with Tinderbox e.g. Note Name and Text
Some text formatting issues when moving between the different steps
It takes much more time that I would like - I would like to copy the Highlights Markdown text directly into a TB Note $Text field and process it from there.
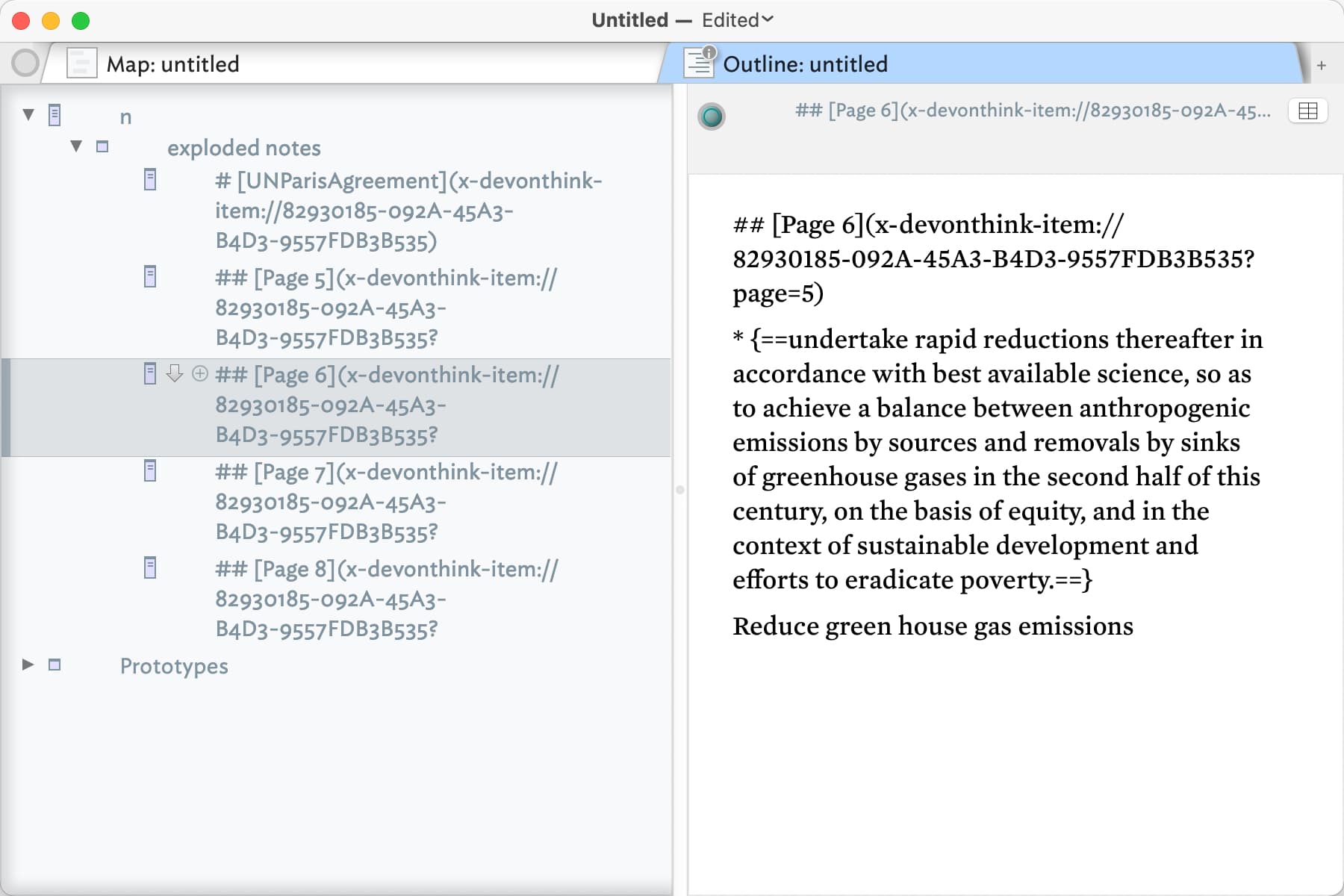
DevonThink also includes the option to export highlights to a Markdown file format. I include an example file below with highlights extracted from the 2015 UN Paris agreement on climate change. The format is somewhat complicated and illustrated below:
Each page has it’s own reference line including information on the page number and direct link to the document page in DT. The follows one or more highlighted text passages delineated by the character sequence {== a the beginning and ==} at the end. The follows an optional description of the quote which I usually use to set the name of the note.
I think this would be a good case to make use of the new string processing action code of Tinderbox perhaps wrapped into a function for the user community. My ideal solution includes:
Creating a new note, one for each highlight
Use the Note name if present as $Name and the highlight text as $Text
If no Note name is present then set $Name to the $Text
Setting the $ReferenceURL of the note to the DT page link
Unfortunately it’s not clear to me how to parse such as file. The main complicating factor is that the page reference is not repeated for each entry and there are a variable number of entries per page. For instance should one Explode the note based on a page delimiter such as ‘##’ and then treat each entry separately via a Stamp ? Or is it better to parse the whole text for the number of entries e.g. via $Text.extractAll("##"); to get the number of entires and then loop through the whole text field with the help of the new string processing functions ?
I’m not sure that’s ideal. Using a paragraph or a very long sentence just gives hard to read/display titles. Perhaps better to use a placeholder which is a prompt to give a short meaningful title. This a congruent which reflecting on one’s notes and helps indicates notes perhaps requiring early attention.
Also too busy here to dive in but…
Annoyingly your source has the desired note name at the end of the ‘item’. Yet, you want it first as it is the string you need to make the new title to make the note. Ah - you’ll have to use a placeholder name and then change the $Name when done.
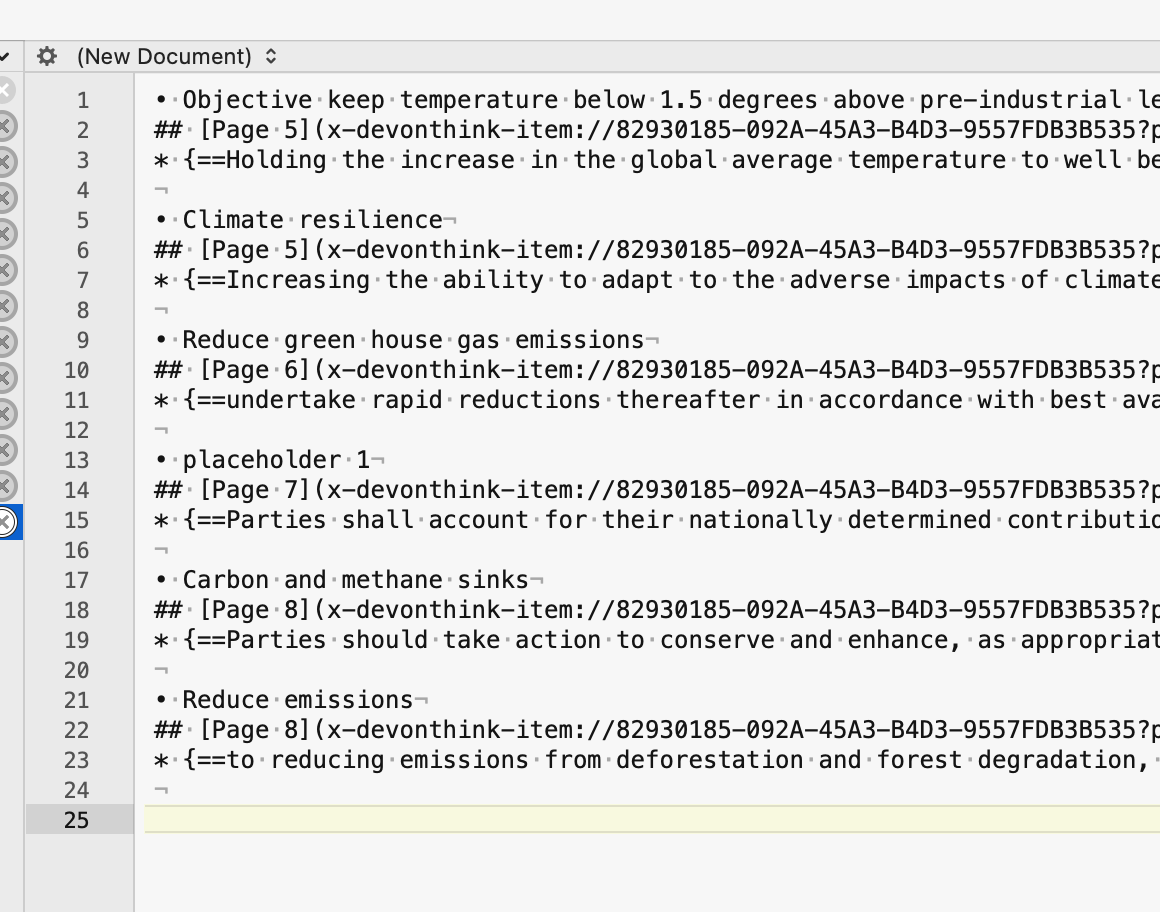
It seems each highlight comprises 3 items, the last of which is sometimes missing:
A line starting with pattern ## [Page \d+] that is the DEVONthink backlink going to $ReferenceURL
A line starting with pattern * {== that is the comment and thus the $Text
A possible line that is the new note name if found.
Yech, it’s worse as the #1 item is not given per highlight, only once per per source DT page.
At this point, i’d look ad editing the DT export script to give you a consistent export format with all three items for every highlight and with the note name as first item giving it a line start marker as with the other two items (making it easier to identify for stream parsing, e.g. pattern ^• , i.e. “• Reduce green house gas emissions”
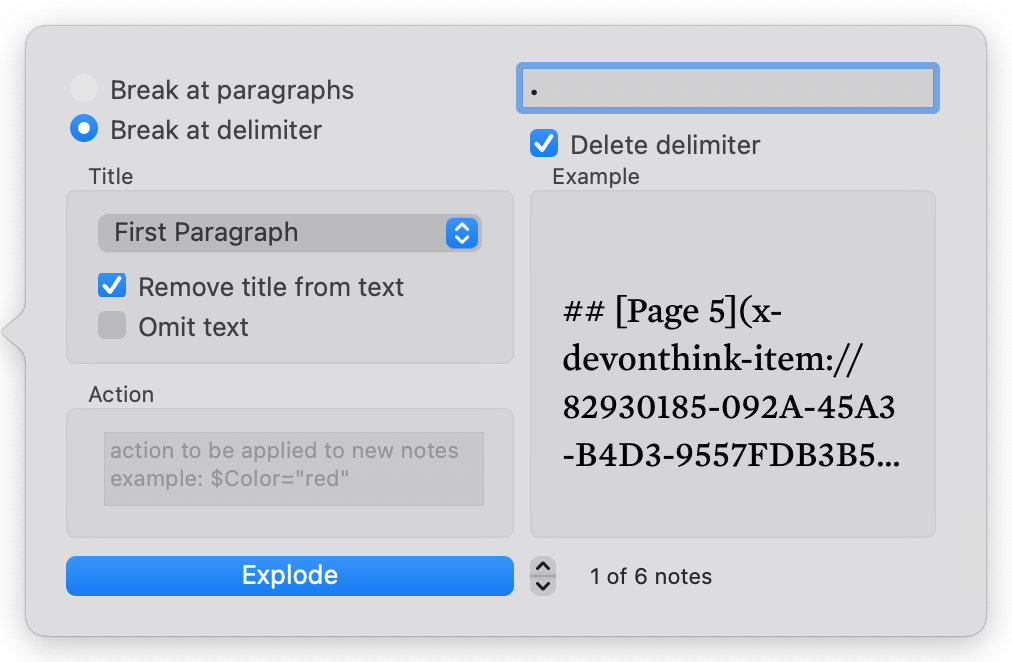
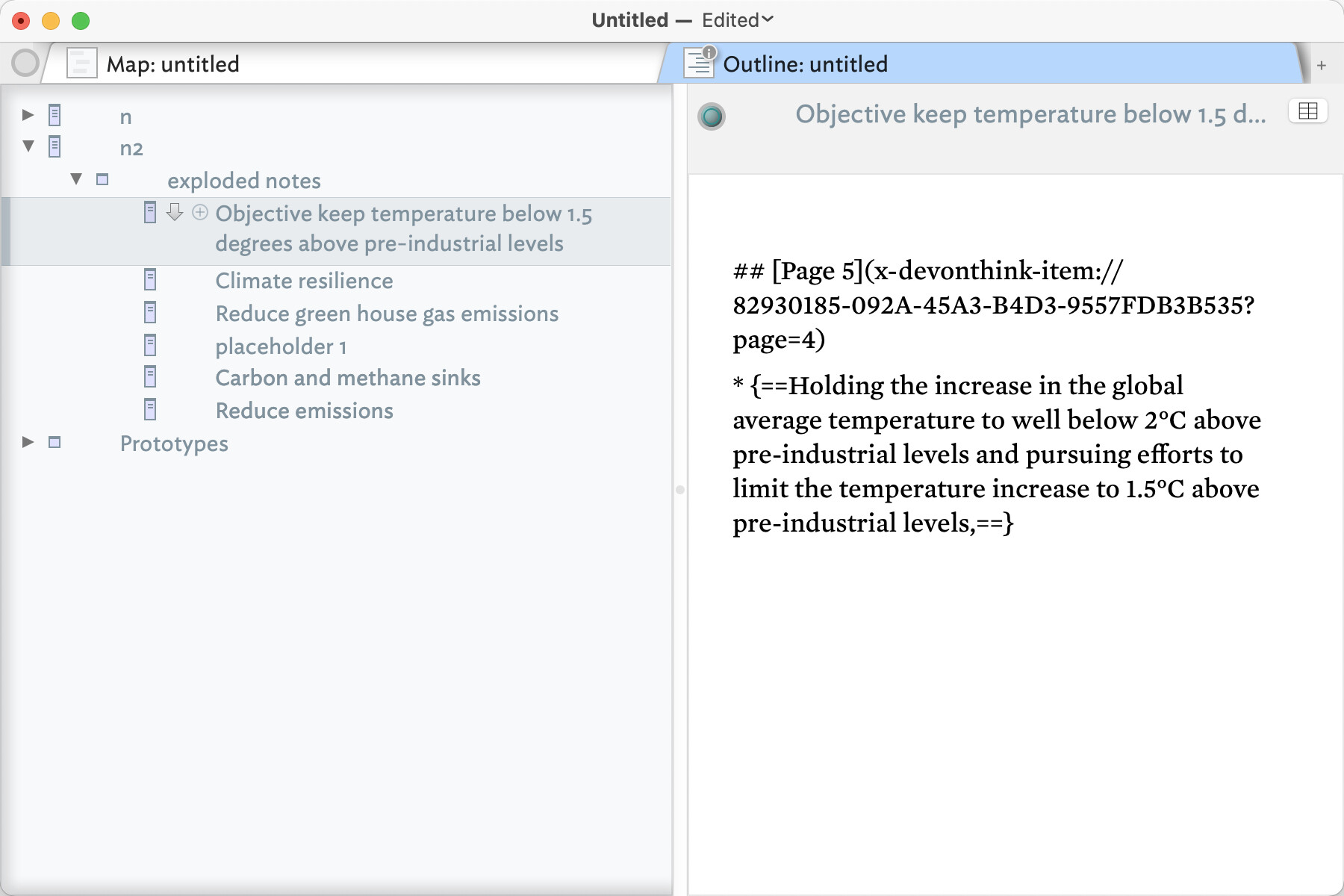
If I take your specimen text, add to a note’s $Text and then on explode on “##” (keeping the delimiter, I get this:
Thanks @mwra and @eastgate. Unfortunately I don’t control the format of the file. It’s a standard hard-coded format not dissimilar from that of the Highlights app.
I was thinking it might be possible to parse using two loops - one for the pages and one for the entries for that page combine with string processing action code.
you could iterate through each page… not tested - just to give you an idea. I would start with seperating each page with all its entries. Then use a RegEx to process each page. This would help with multiple entries on a page.
Sorry for the incomplete (any maybe useless) code samples… just as an inspiration.
I managed to solve a very similar problem - with an approach much like what @webline suggested, namely via RegEx. Details will differ, but perhaps this link helps as a starting point:
Quite understood, but don’t overlook that DEVONthink has AppleScript support. So, even if the current file is a fixed DEVONthink output you could still use a custom export via a script. To do that, I’d take the task to the DEVONthink forums as they are more likely to find you someone who can help with making a more sensibly-structured export document.
I suspect fixing that would save a lot gymnastics at the Tinderbox end.
if you collect the annotations as a table (tools menu in DT) - you get a cleaner export format - like:
|Dokument|Ort|Typ|Annotation|Notiz|Link|
|---|---|---|---|---|---|
|03505-06-S1-002459817|Seite 9|Highlight|Martin Luther, der nie ein Honorar von seinen Verlegern/Druckern angenommen hat, bekennt sich in Worms zu seinen selbst geschriebenen Worten in seinen Bü- chern, er beruft sich dabei auf die Korrektheit des Wortlauts seiner Texte (im Schrift- satz). Jede Abweichung vom 'autorisierten' Wortlaut ist (böswillige) Verfälschung oder (gutgemeinte) Deutung anderer, für die er nicht einzustehen hat. Die Verbrei- tung des Textes durch den Druck schafft den öffentlichen Wortlaut eines Autors.||x-devonthink-item://9161B6C1-C78B-4036-A0FB-2861DF3C1118?page=8|
|03505-06-S1-002459817|Seite 11|Highlight|Johannes Gutenberg (1394/99-1468) gilt als der große Erfinder des Buchdrucks,||x-devonthink-item://9161B6C1-C78B-4036-A0FB-2861DF3C1118?page=10|
|03505-06-S1-002459817|Seite 11|Highlight|gegossenen beweglichen Lettern||x-devonthink-item://9161B6C1-C78B-4036-A0FB-2861DF3C1118?page=10|
|03505-06-S1-002459817|Seite 11|Highlight|die Mainzer Ablassblät- ter von 1454 sind der früheste Druck,||x-devonthink-item://9161B6C1-C78B-4036-A0FB-2861DF3C1118?page=10|
|03505-06-S1-002459817|Seite 11|Highlight|Gutenbergs Erfindung, die schriftkulturell so weitreichende Konsequenzen hatte, breitete sich – nachdem ihr Geheimnis gelüftet war – von Mainz im deutschen Sprachraum geradezu explosionsartig aus.||x-devonthink-item://9161B6C1-C78B-4036-A0FB-2861DF3C1118?page=10|
|03505-06-S1-002459817|Seite 11|Highlight|die ersten Druckereien vorwiegend in Bischofs- und/oder Universi- tätsstädten besonders im oberdeutschen Raum befanden,||x-devonthink-item://9161B6C1-C78B-4036-A0FB-2861DF3C1118?page=10|
|03505-06-S1-002459817|Seite 11|Highlight|die Stadt der Ort des frühen Drucks||x-devonthink-item://9161B6C1-C78B-4036-A0FB-2861DF3C1118?page=10|
|03505-06-S1-002459817|Seite 11|Highlight|Dennoch glichen die gedruckten Bücher des 15. Jahrhunderts noch in vielerlei Hinsicht ihren handgeschriebenen Vorfahren: das Format des Buches und die Anord- nung des Textes entsprachen der Handschrift.||x-devonthink-item://9161B6C1-C78B-4036-A0FB-2861DF3C1118?page=10|
|03505-06-S1-002459817|Seite 11|Highlight|sie malten Initialen mit der Hand in das fertig gedruckte Buch, wo der Drucker ihnen Platz gelassen hatte.||x-devonthink-item://9161B6C1-C78B-4036-A0FB-2861DF3C1118?page=10|
|03505-06-S1-002459817|Seite 11|Highlight|Die Bücher des 15. Jahrhunderts lassen sich mit dem Schlagwort der 'Hand- schriftenimitation' treffend charakterisieren: teuer, traditionell, gelehrt, liturgisch, äs- thetisch.||x-devonthink-item://9161B6C1-C78B-4036-A0FB-2861DF3C1118?page=10|
|03505-06-S1-002459817|Seite 13|Highlight|Im 16. Jahrhundert dagegen, zur Zeit der Reformation, änderten sich sowohl das Äußere als auch der Inhalt des gedruckten Buches: die Druckwerke wurden kleiner im Format, nicht mehr so aufwendig in der Ausstattung und damit preisgünstiger.||x-devonthink-item://9161B6C1-C78B-4036-A0FB-2861DF3C1118?page=12|
First thanks to all the responses. It illustrates how active and supporting this community is. There is useful material and ideas in all the responses of value to the community along with different approaches which align roughly into three categories:
Arrange the text file format via AppleScript so that Explode can be applied (e.g. in the answer from @mwra)
Use of string action code and regular expressions (@abusch and @webline)
Potentially a double loop in action code/functions to iterate of pages and page entries
The latest reply by @webline might be the one with the lowest hanging fruit for an immediate solution without invoking AppleScript or multiple loops. DT offers export in three different formats:
Rich Text
Markdown
Sheet
I had problems with the sheet solution because of the work intensive intermediate step to read it into Excel as csv, edit the headings by hand there and then copy over to TB before exploding etc… I think (@webline to confirm) solution removes the onerous middle step so that new procedure within DT is to i) Summarise Highlights choosing the “Sheet” option and ii) Convert the sheet into Markdown within DT giving the sought after regular structure above. I was unaware of the 2nd step to convert sheets into Markdown format but the results look promising.
I’ll try it out today and report back to this forum.
Copy the text to a Tinderbox Note $Text field and apply Explode to create one note per line. Delete the first two of the new notes which are the headers and apply the following stamp to the rest of the notes
Note the use of offset to address cases in which I’ve highlighted text but not assigned a description. Also for lack of a counter I just give the note a title "Note" in such cases. I realise my code is not going to win any beauty contests here and you are welcome to suggest improvements.
It almost works flawlessly. Here below an extract. You’ll see that the stamp did not extract the information on the final note. I think this is linked to the semi-column in the body text - I’m not sure what the best way is to deal with these cases.
Below the full TB file as a reference. Let me know if you have any ideas to improve the solution and deal with special characters such as semi-column.
11 March 2022: A final update to my procedure above. If I search and replace the character “;” with “-” in the text before Exploding the text into individual highlights I get the desired output.
I consider the new approach to importing DevonThink notes an improvement over the method elaborated in 2020 found in this thread as there is no intermediate step via spreadsheets programme, editing attribute names or exporting the document outside of DevonThink.