I just posted an article on my blog, wippp.com, on how i’m using Tinderbox to manage scholarly information on the microbiome.The blog entry includes a Keyboard Maestro script I built to help export information from Papers.app into Tinderbox.
Nice article. Reading “Although it has taken a significant amount of time inputting the abstracts into Tinderbox” made me think of how I could export all of my relevant abstracts and reference informations in one sweep from Bookends. But, I think it would be better to keep the big database of abstracts (specially if you have a lot of references) inside the reference manager: and pull only the ones relevant to a specific project.
What do you think?
Thanks for the article by the way. I always enjoyed your articles.
1 Like
Yes, thanks for this. It’s a huge asset to the plucky community of Tinderbox users and potential adopters to have these public discussions of how-and-why. (Also by Stephen Zeoli, Dominique Renaud, Mark(s) Anderson and Bernstein, and others who no doubt I’m forgetting at the moment.)
1 Like
Thanks. I’ve actually found it helpful to export all the articles I’ve read. As an example, I know I’ve read numerous articles about Lactobacillus. I use Tinderbox to prompt my memory and connect the dots between different pieces of information. If I look under “Bugs” in my outline, I can see all the mentions of Lactobacillus across my abstracts. Other agents bubble up information about Lactobacillus in other contexts (e.g. in fermented foods or as an anti-inflammatory agent).
If the data remained in Papers or Devonthink, I have to pull the information through a query–using Tinderbox, the connections are pushed to my attention. I can still go back and view the information in the main Papers database, or in Devonthink. The method of using Tinderbox for organization and Devonthink for deeper exploration is working well for me.
1 Like
One more question. Why do you decide to put the reference data into the $TEXT itself. Why not into attributes?
I’m relatively new to working with anything but the outlining feature. Ultimately, the information will end up in Scrivener. I’m not sure of the capabilities of an attribute, but knew I could make things work (both sorting and exporting to Scrivener) using TEXT.
I use the reference metadata in my writing–I’m not sure what would and wouldn’t carry over to Scrivener when I export.
I am hoping others, with more knowledge than I have, can build on what I’ve done (and publicly share their improvements). Ultimately, it’s all about efficiency for me!
1 Like
Yes, it is all about efficiency.
I was thinking, if you put the metadata into the attributes, you could use the agents to group the text based on author or title…etc.
if you remember, for example, John has written something on Ambeba, then, you can ask the agent to filter the notes where John is the author, and contains “Ambeba” as text…
But, as you said, the exporting is simpler without attributes.
Thanks for the clarification. I am also muddling with similar academic stuff: and unsure how to set my resources. That is why I am asking you.
1 Like
Yes, for instance if you had either the author name, or certain keywords involving subject or theme, as metadata – in fields (attributes) named $Author or $Theme or whatever you preferred – then you could use the extremely powerful Attribute Browser to auto-group your entries by those criteria.
When I am assembling notes for a book, I make ample use of $Theme or $Chapter or $Topic fields, which I assign manually. But you could also do this with the same agents you’re using to scan the text now. If the $Text contains a certain key word or phrase, you could have the agent assign a corresponding value for $Theme etc. Part of the incremental-formalization process.
3 Likes
Can you elaborate on these a bit?
- Why not put the abstracts in DEVONthink and use smart groups? What does Tinderbox give you in this case that DEVONthink doesn’t? You mentioned not wanting to do queries, but smart groups act like super simple agents for text search.
- Why do you only include the abstracts in your Tinderbox document, and not the individual highlights / notes?
- What do you mean by “DEVONthink for deeper exploration?”
- What do you mean by “moving to DEVONthink as the idea evolves?”
@JFallows: I knew about the attribute browser from your comments. So far as I can tell, you are also the only person who often mention it. I personally never tried it. I would appreciate if you can drop a small writeup explaining on how you use the Attribute browser.
1 Like
Pat
I’ve used Devonthink for years. The folder paradigm of Devonthink doesn’t work that well for me–especially early in the writing process. I am overwhelmed with the amount of information Devonthink digs up. Call me old school, but I prefer a traditional outline view. The outline view helps make me feel more organized. I still use Devonthink, but at a later stage of the writing process.
As I cover in my blog, I extract annotations and highlights and capture them as individual files in Devonthink. In fact, all my highlights, annotations and pdfs are in Devonthink. I’ve been using Tinderbox in the early stage of writing to help me organize my thoughts. Once I have a skeleton outline, I start to fill in the flesh from Devonthink. During my use of Devonthink I make heavy use of the “See Also” button. Does this make sense?
I understand I’m trading away power and flexibility, but my system really is working for me.
2 Likes
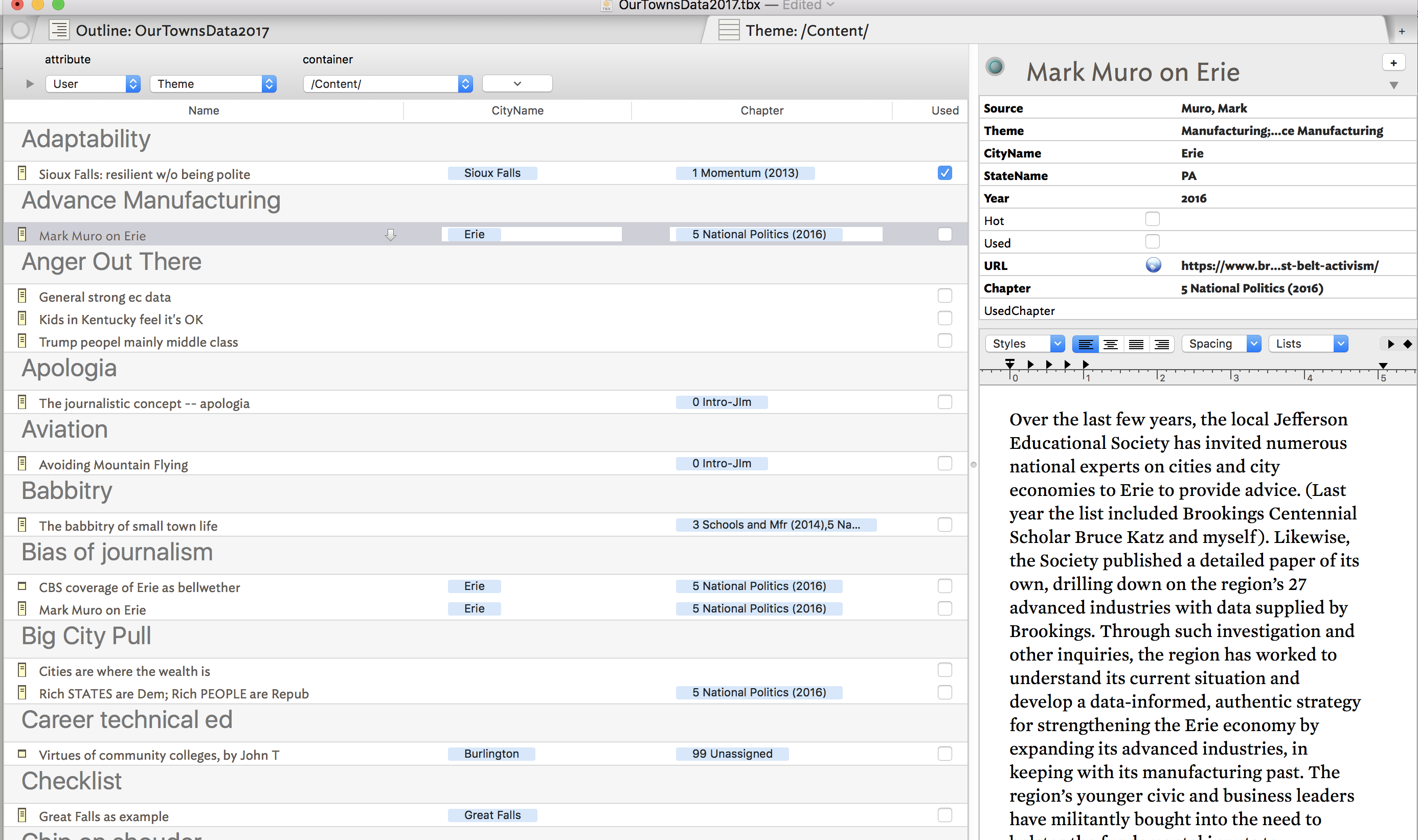
Here you go.
This is a screen shot of an Attribute Browser view, in which:
- I am grouping entries by $Theme
- I am showing some other info in the various columns in the view
- I have the text pane at right, to show the contents
I find this incredibly useful and powerful – the ability to group notes by whatever attribute or field you choose.
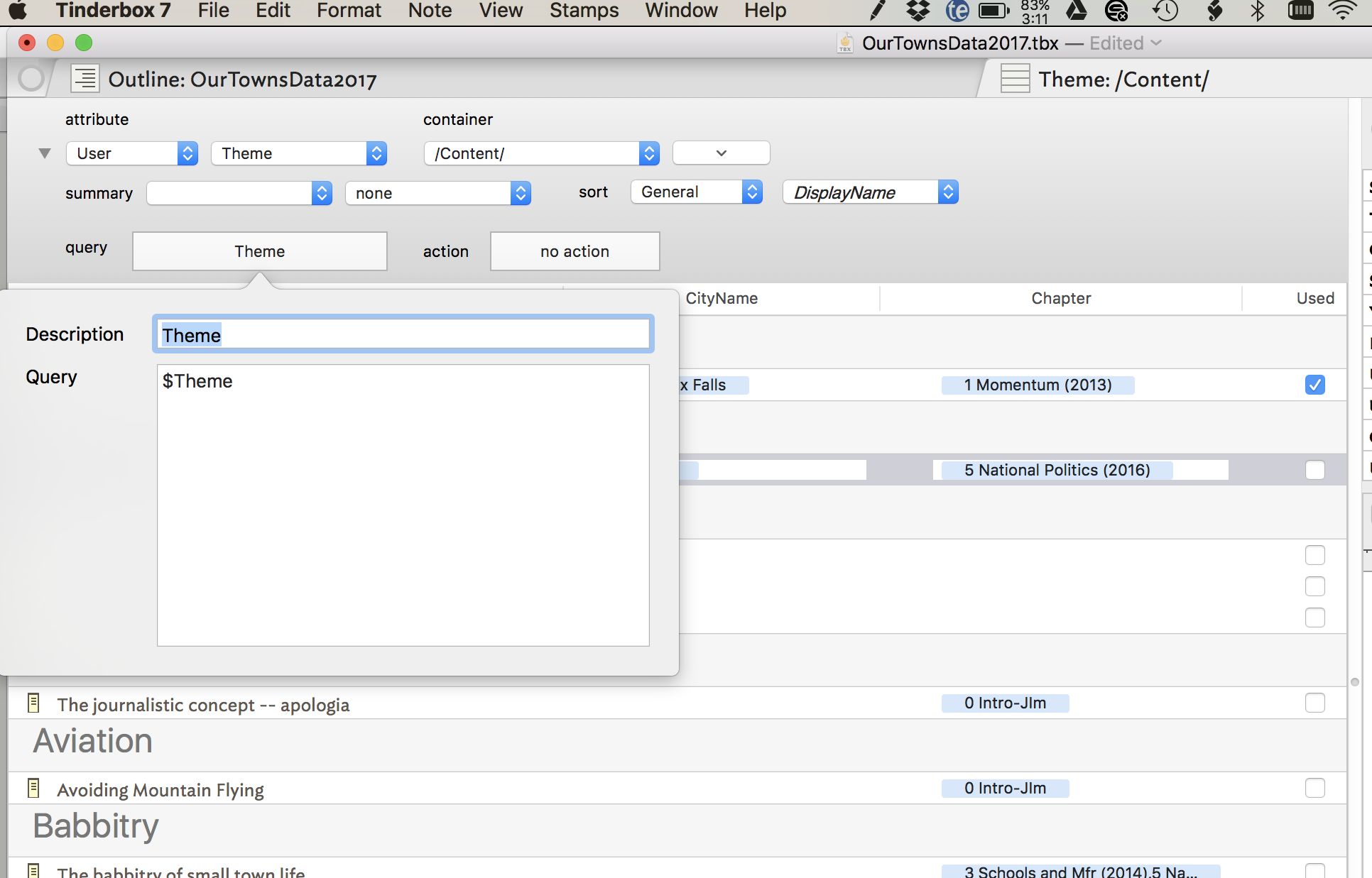
Bonus: Here is the same screen with the query field expanded. This shows that I am looking only for entries with some value in $Theme. You can construct the query any way you would like, including with some very elaborate queries.
5 Likes
[quote=“jtaekman, post:11, topic:389”]I understand I’m trading away power and flexibility, but my system really is working for me.
[/quote]
I’m just trying to understand your thought process – you’ve obviously put a lot of thought into this, and thank you for sharing!
fwiw I think DEVONthink and Tinderbox both offer different kinds of power and flexibility, so I’m always trying to learn more to put them to good use.
I think I’m starting to see where you’re coming from now… you use DEVONthink to help you find relevant information, and Tinderbox to organize it.
That makes a lot of sense, and helps me understand how I can better use these tools together. Thanks!
3 Likes
Thanks for sharing the article.
RE:
One nice thing about attributes is that a bit of redundancy won’t create problems in your file. So if you want to experiment with adding author, title or tag (etc.) information to an abstract’s attributes, you could do so without removing that info from your $Text. If the info remains in both places experimenting wouldn’t mean having to change any of your agents or workflow. Neither would it mess up your current export process.
It’s probably bad luck to say this, but as long as you aren’t deleting info, I think it’s hard to mess things up by playing around. The worst you’ll get is chaos and TBX makes that very easy to fix.
For what it’s worth, when I first began moving info from Text to other attributes, I relied almost exclusively on boolean user attributes. I created things like “TextRead,” “TextCited,” “Irrelevant,” put them in the key attributes listed above my note text and could manage them with a checkbox. They were simple to manage and very useful additions to existing agent queries.
1 Like
New to both Tinderbox and the forums, I wonder if you have written about this process somewhere?
Is that annotations and highlights made in pdfs? How to you extract them as individual files?
That’s covered in a linked article – he exports one file and splits it, but there’s a comment with an idea of how to export all annotations as separate files.
2 Likes
Thank you @JFallows
This is really helpful.
I was about to ask you to put the note in a separate topic. That is too much to request. I am going to do it myself. I will then ask you questions.
Wasn’t there a “related notes” or a “see also” button in Tinderbox in the past? I could have sworn there was something like that. Has it been taken away?
Yes, in the Get Info panel (opened via the contextual menu, right-click or control-click) we have the Similar tab. There are also the similarTo("Item",N) operator and the ^similarTo( item, count[, start, list-item-prefix, list-item-suffix, end] )^ HTML export item.
In GetInfo we also have the Words tab. When a word in that view is clicked, we can see a listing of the notes where that word occurs.
And another option for finding relations to a note is the Roadmap and Browse Links items, also in Get Info.
4 Likes