raganmentioned using TB in place of Maxqda. I remember a similar issue has come up in the old forum–whether to use NVIVO or TB for data analysis—mostly for getting concepts and conceptual connections in documents. I myself have been wondering about this for a while. You can see the thread in here for example.
My position has been TB requires a lot of processes (like, turning your documents to Doc or other text files) to serve as a qda application. Most academics rely on PDF files. TB not very much friendly with PDF files. We need some means of annotating and exporting text files from PDF sources to use the power of TB. Sense created the best environment as it was able to break annotations into small chunks. Skim also generates fairly good exports. The standard process is we have to export annotations and explode them in TB. It is doable. I personally have been doing it for a long time. Devonthink made the process a bit smoother as it accepts Markdown files (best export format for Skim) and converts them to rtf files (best import format for TB). But, the process could be hard to maintain in the long run. I have struggled. Furthermore, the explode machine is mechanical. It can break paragraphs; but, cannot see concepts. I want to compare the concepts, not necessarily the paragraphs. That is where QDA applications excel. Concepts can get lives. Concepts start to live by themselves in qda applications because I can code them, write a complete story about them; I can develop them fully. The system is built to zoom into (focus, magnify) the pieces of concepts (which could be a mere word, a sentence or paragraph; inside a word document, a text file, or a PDF document; even within a video). The code gives the concepts a full life. Memos develop it to a full being. But, there are things I would miss in a QDA application. The smartness that TB pack is not there (yet).
A better option I have been thinking about is using TB alongside a dedicated QDA applications such as ATLAS TI and Maxqda. These applications can export clean texts; with coded tags. But, the question is why. My impression is if I am going to use Atlast TI, really, I don’t need to export my text (quotations) to TB as the maps in Atlas are almost as good as the one in TB (ATLAS ti Mac - An Overview (Extended Version) - YouTube). But, there are good reasons to avoid AtlasTi. Their licensing is dangerous; even out right sinister. Maxqda, on the other hand, is a great qda application. But, it has weaknesses on the mapping side. The maps are nowhere close to the maps of TB. Therefore, for people using Maxqda and TB, it is possible to use the best of both worlds by exporting the coded data from Maxqda to TB. But, again, one can question if the process is maintainable in the long run.
What do you guys think of using TB as or along with a qda application?
I have not used ATLAS, but MAXQDA became very sluggish after loading a few PDFs. I try to minimize using PDFs and annotation software. It seemed to be taking me further away from the actual writing that I needed to do. I started out using them, but my workflow evolved over time especially in the later stages of my dissertation. After I conducted the initial analysis using TBX and text, OmniOutliner became my go to application for PDFs and chunking of text. Although not well documented, OminiOutliner 5 allows linking of PDFs to topics. So I now have a single OmniOutliner document that contains all of the references that I used in my dissertation with the associated chunking for each topic. All searchable. OO 5 also allowed me to create one to many relationships. One PDF linked to many topics. OO 5 also has hoisting capabilities so when I finished a topic I exported it and all its chunks to OPML. From OPML, I could pull the topic into many other tools that produce a readable time stamped document in PDF. And I am ready to write. I used WorkFlowy for this last step, but all the online outliners have this capability. Checkvist and Dynalist do the same. I suppose I could pull them into Tinderbox and create a map, but my main focus at that point was writing.
Why do you load the pdf directly into the Maxqda database? I haven’t tried Maxqda 11; but, version 12 supports linking (indexing) the pdf (keeping it outside the database) just like Devonthink. That why you can keep the app fast. The database also remains small.
But, it is intersting you are using OO. I find it not very useful; given it lacks graphical presentations of connecting ideas. It might be my own learning style: I like graphical means of relating ideas: not using hyperlinks or outlines. That is why I like TB and these QDA applications.
I also don’t see the point of linking pdf files to topics. how is different or better than simply tagging the pdf files in Finder (Devonthink) and collecting them around the tags (like topics)?
QDA applications permit you to link paragraphs, sentences and words (concepts) across documents and within a document. Your linking is more or less like tagging in Devonthink. You can tag (link) the whole document; but, not the fragment of concept within the document. That is my main reason for trying QDA appliactions. Concept (paragraph, sentence)-based linking (tagging=coding): more fine-grained relatinoships than document based tagging.
I agree with your point of slowing down in the process of writing. It takes a lot of time to inspect, read, tag (code) the documents using Qda application. I also have that worry.
It would be nice to see the experience of other users in this area.
Now I think of it in those terms - I’ve been using Tinderbox for as my primary QDA tool though my Web Science Masters and now PhD study. Amongst other things I’ve used Tinderbox to analyse:
the helpfulness and (mis-)behaviour in Openstreetmap’s various fora (mailing lists, phpBB, OSQA).
use of and patterns in transclusion in Wikipedia (my paper at Hypertext’17 just recently).
analysis of bot use in Wikipedia (ongoing research)
I too have free access to Envivo. We did tutorials with it during my Masters. I found it overly complex and inflexible. However, were I a pure humanities person - and less comfortable with code/scripting - I think it is perhaps a less scary option. However, for me Tinderbox trumps as a tool as it is so supportive of emergent structure and forgiving of the research need to go back and insert new fields/attributes for newly discovered aspects of the research. I would admit that making the most of QDA in Tinderbox requires having - or acquiring - some Tinderbox expertise. The latter is because the reporting/export of the resulting data does take one into use of action/export code. Fear not though, for those less expert the forum is here to help with just such problems.
Postscript: my analysis is less directly foccussed directly on text, so thus I’m an edge case for normal QDA.
I used tagging in the past, and I know it is popular. However, I find that I use it less and less. Partly for the reasons that David Weinberger (2007) outlined in his book titled Everything is Miscellaneous. I use OO because its practical. It allows me to review material, and take notes on every paragraph and code the related source. It also helps me to maintain and quickly reference the context in which the text was used. Using two monitors, I display the linked pdf document I review on one monitor and OO open on the other. I use Devonthink primarily for storing PDFs. Graphical representations are helpful. I use them to a point (early stages of constructing a writing project to get me going), but again at some point, the desire and the need to write is where I want to spend most of my time. At least for me, when the writing process begins, the graphical representations become secondary and less useful. They also become quickly outdated requiring a certain level of maintenance to keep them current.
@regan Could you kindly elaborate on how you link OO to PDF Files or topics respectively. As you’ve mentioned yourself it seems to be a not so well documented feature so I guess we all can learn a lot from how you managed to get this going. It sounds very interesting. But honestly, I don‘t have the slightest idea of what you are talking about … but I really would love to understand and learn.
What do you guys think: What‘s the main difference between QDA-Software and Tinderbox. As far as I can see: QDA is for analysing already existing sources while Tinderbox is actually assisting in generating content. Or am I mistaken?
Tinderbox is rather nice for qualitative data analysis. I gave a demo and did a panel, years ago, at a conference on computer-assisted QDA, and while dedicated tools have advantages, Tinderbox gives you some great visualization tools and a ton of flexibility.
Partially true. It is true that Tinderbox is best for generating new ideas and creating connections between them. But, the QDA applications can also do exactly that.
Atlas Ti and MaxQDA can definitely be used to generate new ideas (drafting a dissertation), thanks for the noting taking and concept mapping features packed into these apps. Not only generating new ideas, you can also surely draft a paper or a dissertation inside AtlasTi.
The difference, in my view, lies on the higher programmability (unlimited attributes assigned to notes) of Tinderbox and ability of the QDA applications to directly analyze primary documents (such as PDF files and videos).
I think this sort of discussion is needed in order to help ourselves to really understand more and better what one can only do in Tinderbox. For me it is not so much about drafting dissertations and the like. Tools like Atlas Ti oder MAXQDA or Tinderbox are interesting especially when it comes to support or even jump-start the thinking-process.
And I think I learned that even Atlas Ti as the time being has rather powerful tools for visualising ideas.
So, if I understand it correctly: Being able to assign unlimited attributes to notes as the unique feature of Tinderbox … Hmm … well, that really wouldn’t convince me and win me over. Especially when you think that what in QDA-Contexts is referred to as Coding, that is: assign Tags to every word, sentence or paragraph isn’t as easily done in Tinderbox as it seems to be in Atlas Ti or MaxQDA.
So, I’d really love to know what @eastgate did present on a computer-assisted QDA conference and how the discussion about the different tools and approaches turn out. The sheer mentioning of the respective conference contribution certainly pushes but definitely does not satisfy my appetite for knowledge and insight.
By “higher programmability”, I don’t mean just the attributes; you also have to think of the agents and other smart tools such as the smart adornments, OnAdds etc. Advanced scripting o the type we have in Tinderbox is not possible in these QDA apps. Saved searches, in combination with tags (codes) do help; but never as sophisticated as the tools in Tinderbox.
For me, the biggest hurdle with Atlas Ti is the license. It is extremely expensive, and totally evil because once you forget to export your data before your license expires, you are out of luck. And, most attractive part of QDA apps is the strong connection between primary documents (annotating and commenting on them) with the idea generating systems (such as tagging/coding, commenting and writing a memo).
[strikethrough is an edit by the forum moderator at request of OP. The need for correction is explained in posts 28 and 29 below.]
The biggest hurdle in Tinderbox is the big disconnect between primary sources (reading materials) and the tinderbox notes. It is a lot of work to try to annotate a pdf and try to convert the annotation into usable Tinderbox note.
This seems to be very much to the point, @Desalegn. Thank you for that.
Let’s see whether some smart people around here can help us with that: Is there a way – through incorporation of, say, Devonthink or MarginNote and the likes – to mitigate the disconnect between primary source and tinderbox notes?
And still: I’d love to learn what @eastgate found out in conversation with dedicated QDA experts comparing Tinderbox and QDA-Software.
As I wrote, @PaulWalters: I think we need to know, understand and be able to explain why and how Tinderbox can support our thinking process. As long as I have been following this as well as the old forum I really learned a lot about the techniques and different approaches of how to incorporate certain display/view options etc. I really like this and benefitted a lot from that.
But from time to time there are discussion like this one here arising that really never actually seem (!) to lead us anywhere.
So asking @eastgate for sharing his experience what it has been like to be in the arena and discuss with non-Tinderboxer advantages and disadvantages of QDA-Approaches etc … seems to me/be a rather interesting starting point, don’t you @PaulWalters?
But following your call, @PaulWalters: For me Tinderbox is a Tool unlike any other tool that really is agnostic to all the frameworks other tools offers due to one good reason: At the very beginning – no one knows one thing … and yet has to start somehow - somewhere. This “somehow-somewhere”-spot for me often is: Tinderbox. And even further: Sometimes Tinderbox is the dojo to unleash myself from where I got stock in more strictly framed environments such as Outliners or Mindmappers. I really like Tinderbox being a remedium, a remedy – so to speak – in this respect.
A - Data in
That said: There comes a time through such work where I really need to bring in some resources that aren’t always available as neatly formatted CSVs. So in such moments a deep integration with Devonthink or Airtable seems unavoidable in order to bring the data in. But then one starts to not only look at the data brought in but wants to work with it … and here I do agree with @Desalegn: Not being able to really touch (that is: tag, annotate) the data in Tinderbox is a hindrance.
B - Data out
And then time and again we find statements like this one. I think those aspects like not being able to grasp how to export things immediately is nothing that boosts creativity but much rather tends to get in the way. Having software that is – here and there – rough around the edges really isn’t the problem. An aspect, however, others might even call a problem is, when Tinderboxing in the end means something like: Yeah, there are actually good and easy solutions for certain aspects (let’s keep calling them “Exporting Files”) but every one has to either figure them out for oneself or has to search the forum. This is the point where people start to wonder whether they’ve gotten into a Linux suburb where every good IT-gardener of course has compiled her or his own kernel.
Pointe
Tinderbox is a Thinker’s Tool …
But it often confronts the Thinker with problems that really shouldn’t be problems anymore (since they have been discussed and solved already without being easily retrievable), namely:
bringing data in to be mingled with the ab-ovo-thoughts instantiated or incubated in Tinderbox
and then again, after having finished the “Thinking” in Tinderbox, getting data out
Getting answers to these question by no means will compromises anyone’s creativity but rather assures to eventually getting things done, over and over again.
Unfortunately, both of the scripts are not officially supported. Pat has already abandoned his script. Annotation Pane is so far robust, but can break at any point.
Edit: Gladly, @Pat doesn’t abandon the PublishToDEvonthink script; I misread his comments.
I use Tinderbox as a QDA tool to analyze (Chinese language) interviews and legal documents - after previously exploring (and struggling with) atlas.ti and maxqda for the same purpose. My workflow was actually inspired by a video you mentioned in another post: Survey software + Tinderbox - #8 by andreas.
I create plain text files of the primary sources I want to analyze and copy them into TBX.
I “explode” these notes and then assign a prototype to the fragments (which inherit some of the meta data of their original source).
Finally I process these fragments one-by-one, adding notes and assigning tags, categories and occasionally links to them.
After all fragments have been processed, I retrieve the information using the Attribute Browser and use “Copy Note URL” to link to important notes in Scrivener etc.
This works for me because I don’t have visual or video data to analyze (or, for that matter, PDFs) and the granularity of a sentence-based analysis suffices for my purposes.
I think it would help to map some terminology/concepts here. To my understanding…
QDA coding == ‘keywords’ == ‘tags’
Not all ‘tags’ need to live in the same attribute (Tinderbox) or field (most other (database) apps).
Just because app A can’t export in a format app B can’t import doesn’t imply an error on app B’s part. Note: this is a common failing in the context of app A—failing to consider how app A’s users might use app A’s data to do real work outside app A. (I note this as the “…but App A does this…” meme that crops up a lot here.
tags/keywords are simply metadata. Just because some apps stuff actual discrete strands of metadata into a single bucket (e.g .‘tags’) doesn’t meant that in a more capable environment that these shouldn’t be separated. If you want to do analysis in Tinderbox constantly trying to figure $Tags("some tag value") is a very inefficient way of working. It also make for less rich export to downstream apps, e.g. your main writing environment.
I only note this as so many threads here unfairly punish Tinderbox for it’s ‘failure’ to cope with design failures in apps upstream in the analysis process.
I use Tinderbox for QDA precisely because its not a ‘pre-configured’ analysis space. I add attribute(s) as my analysis reveals emergent structure, i.e. adding user attributes as when needed. I add values (‘codes’) to said attributes as pertinent. If existing attributes show divergent stands of metadata, I add new attributes. That doesn’t preclude storing the same values in $Tags as an ‘everything’ bucket—but experience has taught me the latter is a very inefficient/unproductive form of tagging/coding of source data.
For any given [attribute] value, Attribute Browser gives you a summary view, a QDA aspect most overlook as in a QDA app it’s likely hard-wired into the main interface. By comparison Tinderbox is a data toolbox - use the bits you need.
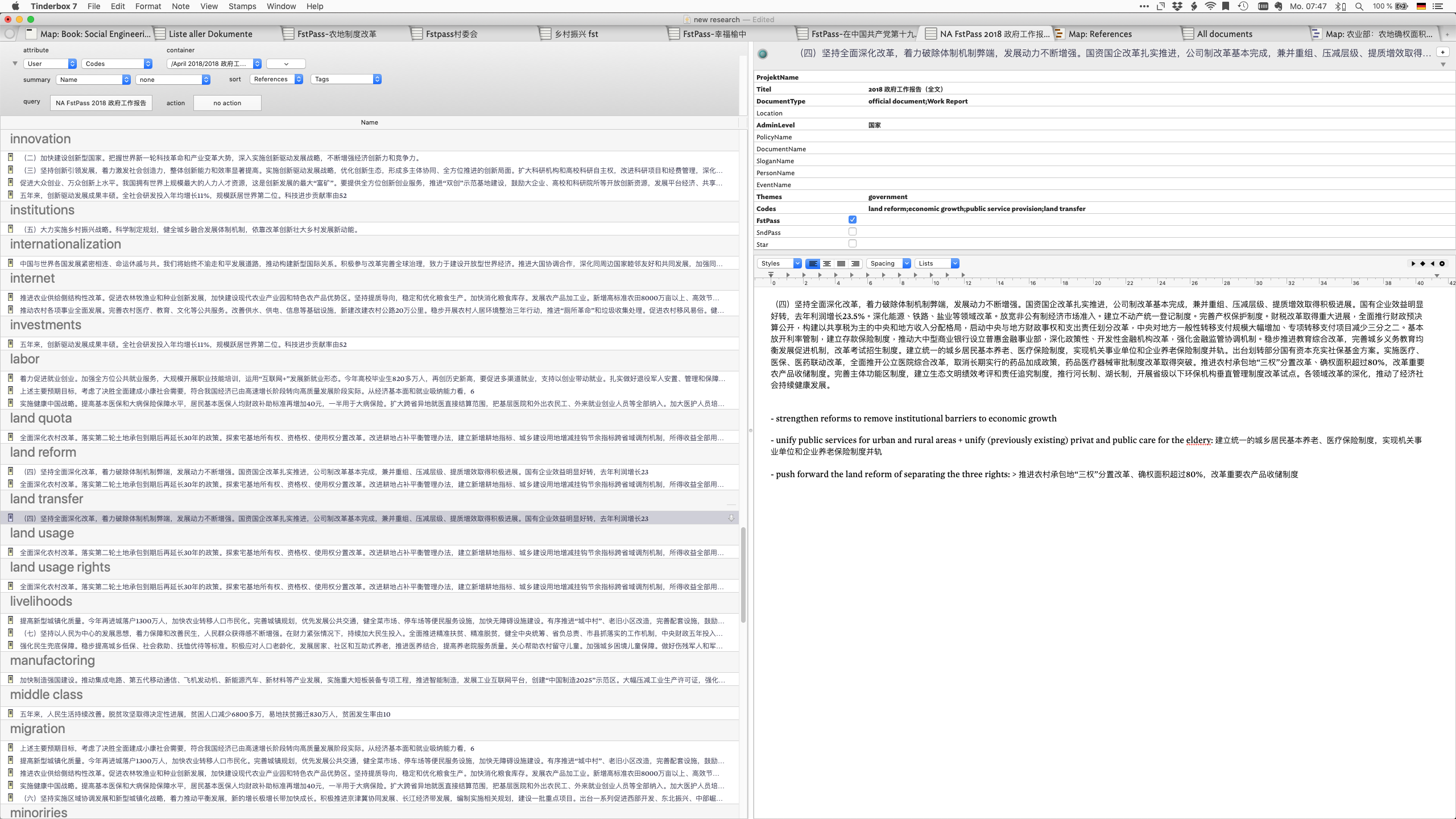
I usually add my notes to the end. This one is from the 2018 Work Report, a semi-legal document. I intend to process all of these fragments twice, hence the existence of Fstpass and SndPass.
Thanks for the example. Always interesting to see how people approach working with data and sources. I often get useful ideas even if my needs aren’t exactly the same.
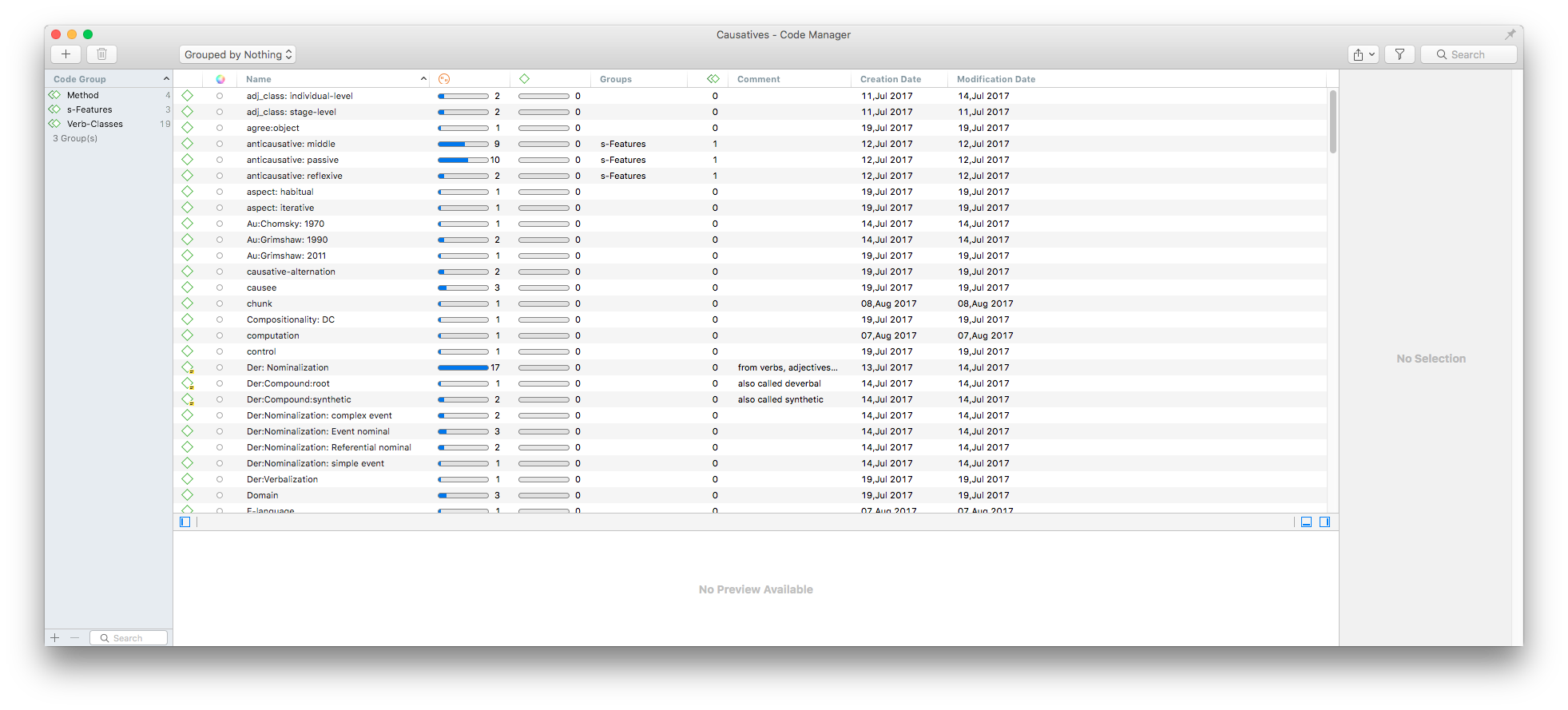
The attribute browser in Tinderbox is actually the same as the Code browser (Code view or Code Manager) in the QDA apps. The QDA applications often have a dedicated browser/view/manager for the code (tag).
Here is the code browser (manager) in Atlas Ti
you can filter the codes in the code browser
you can also create the mind map of the codes (tags)–which is not possible in Tinderbox
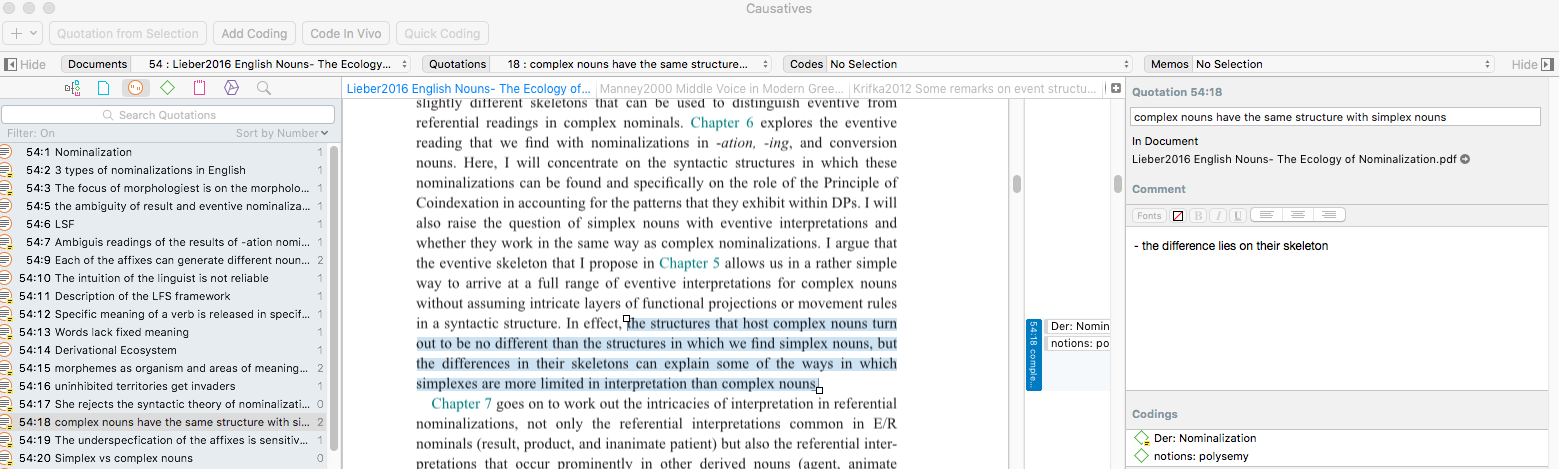
The Code browser is not necessarily hard-wired in the main interface either. You can hide the code browser or the Code view if you want to focus on reading and annotating process in Atlas Ti, for example. IN the following picture, I am using on the Quotation view (lists all the quotations from across all the reading documents; or the ones within the currently activated document, based on one’s filter).
My favorite part in Atlas is the fact that I can give a name for my quotations, write a comment (or reflection on them), and finally code them. THE reflections are collected in one category; the quotations are collected as well, and then, the codes link concepts from one PDF document to the other. It is a very coherent and unified system. The memos are great to start drafting your new paper (growing out of the reading material). The Memos are like the Notes in Tinderbox. They keep the ideas for themselves but can be compared and linked with other Notes (Memos) in the Concept map for figuring out connections.
As I said above, the main strength of Tinderbox is the advanced scripting capability. The drawback, in contrast to the QDA apps, is the inability to use the primary sources. In Atlas Ti, everything is integrated. The tags (codes) assigned on the Pdf file or the video, are the same codes that I assign to my own notes (called memos). There is no gap between the primary sources and the secondary material. That is a huge advantage for people who don’t want to mess with exporting annotations from primary sources (pdf files) to text (rtf) notes.
for scholars who have their data/material in text(spreadsheet) format, Tinderbox is the way to go.
For those who want to annotate primary sources; and then tag and annotate them, and write new ideas based on those sources, or analyzing those sources, QDA apps work better.
Like anything else, there are always drawbacks to any of the systems.
the concept mapping in the QDA apps is not as flexible as the one in Tinderbox. It is different. You cannot drag some elements into the map; this was especially true for MaxQDA 12. I haven’t checked the latest version.
Atlas TI is definitely the best QDA app because the software offers the most convenient environment to read and annotate PDF files. But, the license is extremely expensive, even with their student discount, it is not affordable for most of us. There is also a possibility of losing all of your data because the software doesn’t export once the license expired.